 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Real-Time Cultural Transmission without Human Data
Mar 01, 2022
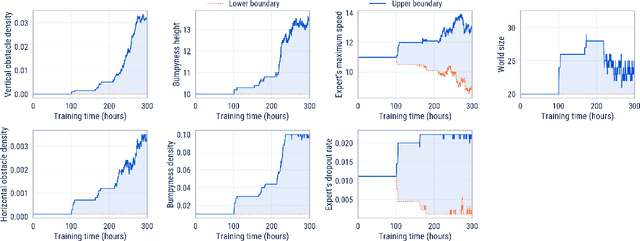
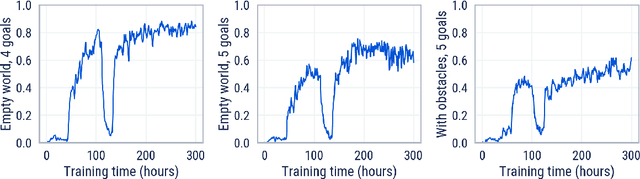
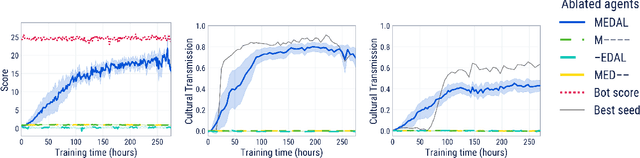
Cultural transmission is the domain-general social skill that allows agents to acquire and use information from each other in real-time with high fidelity and recall. In humans, it is the inheritance process that powers cumulative cultural evolution, expanding our skills, tools and knowledge across generations. We provide a method for generating zero-shot, high recall cultural transmission in artificially intelligent agents. Our agents succeed at real-time cultural transmission from humans in novel contexts without using any pre-collected human data. We identify a surprisingly simple set of ingredients sufficient for generating cultural transmission and develop an evaluation methodology for rigorously assessing it. This paves the way for cultural evolution as an algorithm for developing artificial general intelligence.
Machine Translation Decoding beyond Beam Search
Apr 12, 2021
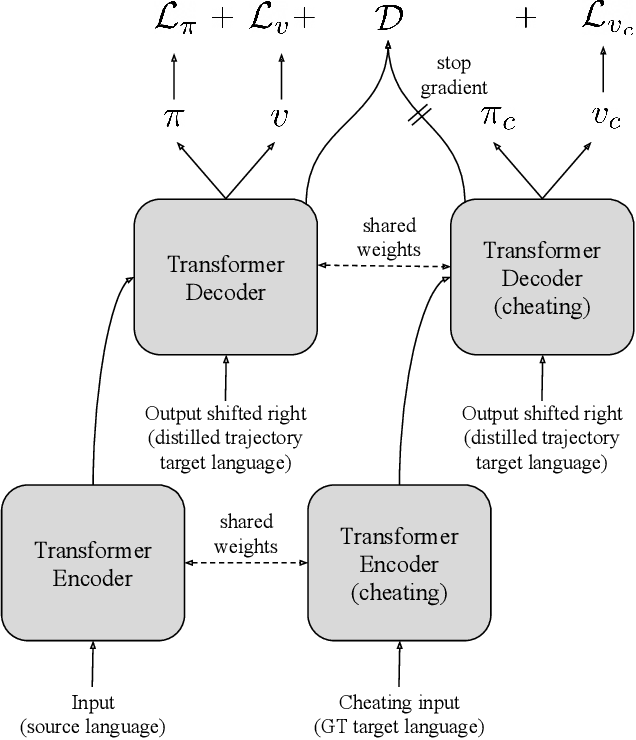

Beam search is the go-to method for decoding auto-regressive machine translation models. While it yields consistent improvements in terms of BLEU, it is only concerned with finding outputs with high model likelihood, and is thus agnostic to whatever end metric or score practitioners care about. Our aim is to establish whether beam search can be replaced by a more powerful metric-driven search technique. To this end, we explore numerous decoding algorithms, including some which rely on a value function parameterised by a neural network, and report results on a variety of metrics. Notably, we introduce a Monte-Carlo Tree Search (MCTS) based method and showcase its competitiveness. We provide a blueprint for how to use MCTS fruitfully in language applications, which opens promising future directions. We find that which algorithm is best heavily depends on the characteristics of the goal metric; we believe that our extensive experiments and analysis will inform further research in this area.
Seeing Both the Forest and the Trees: Multi-head Attention for Joint Classification on Different Compositional Levels
Nov 01, 2020

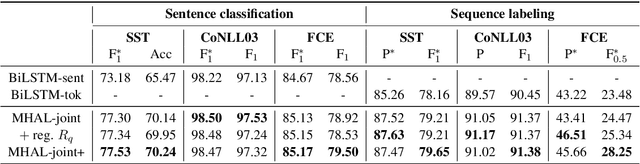

In natural languages, words are used in association to construct sentences. It is not words in isolation, but the appropriate combination of hierarchical structures that conveys the meaning of the whole sentence. Neural networks can capture expressive language features; however, insights into the link between words and sentences are difficult to acquire automatically. In this work, we design a deep neural network architecture that explicitly wires lower and higher linguistic components; we then evaluate its ability to perform the same task at different hierarchical levels. Settling on broad text classification tasks, we show that our model, MHAL, learns to simultaneously solve them at different levels of granularity by fluidly transferring knowledge between hierarchies. Using a multi-head attention mechanism to tie the representations between single words and full sentences, MHAL systematically outperforms equivalent models that are not incentivized towards developing compositional representations. Moreover, we demonstrate that, with the proposed architecture, the sentence information flows naturally to individual words, allowing the model to behave like a sequence labeller (which is a lower, word-level task) even without any word supervision, in a zero-shot fashion.