 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Machine Learning Models Fail to Fully Capture Epistemic Uncertainty
May 29, 2025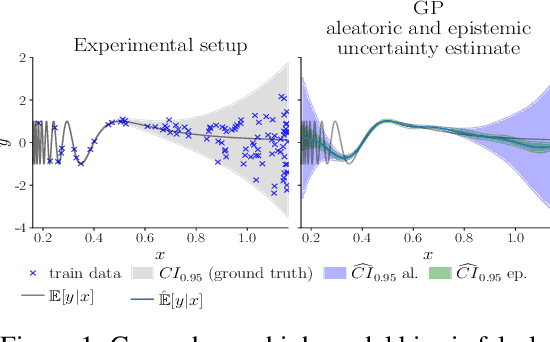
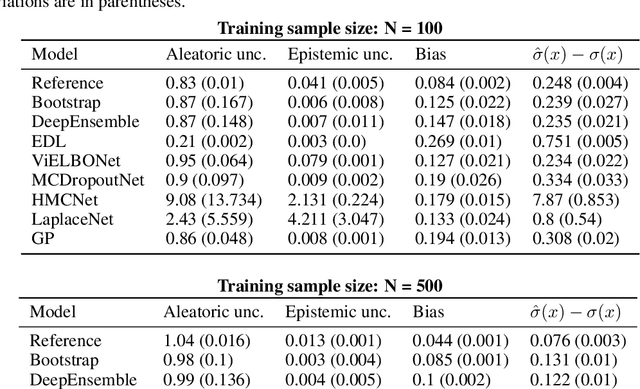
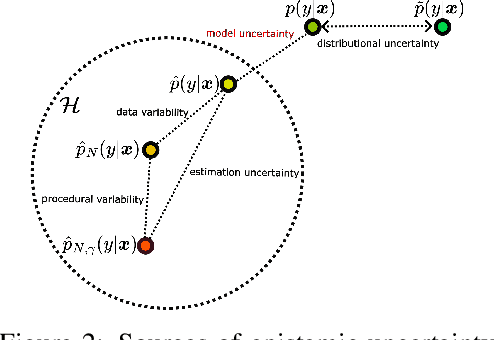
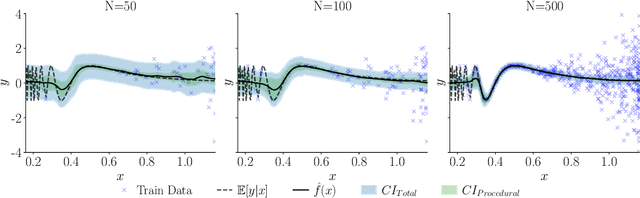
In recent years various supervised learning methods that disentangle aleatoric and epistemic uncertainty based on second-order distributions have been proposed. We argue that these methods fail to capture critical components of epistemic uncertainty, particularly due to the often-neglected component of model bias. To show this, we make use of a more fine-grained taxonomy of epistemic uncertainty sources in machine learning models, and analyse how the classical bias-variance decomposition of the expected prediction error can be decomposed into different parts reflecting these uncertainties. By using a simulation-based evaluation protocol which encompasses epistemic uncertainty due to both procedural- and data-driven uncertainty components, we illustrate that current methods rarely capture the full spectrum of epistemic uncertainty. Through theoretical insights and synthetic experiments, we show that high model bias can lead to misleadingly low estimates of epistemic uncertainty, and common second-order uncertainty quantification methods systematically blur bias-induced errors into aleatoric estimates, thereby underrepresenting epistemic uncertainty. Our findings underscore that meaningful aleatoric estimates are feasible only if all relevant sources of epistemic uncertainty are properly represented.
A calibration test for evaluating set-based epistemic uncertainty representations
Feb 22, 2025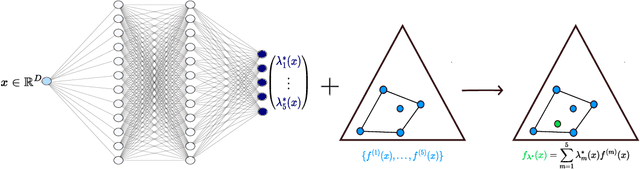

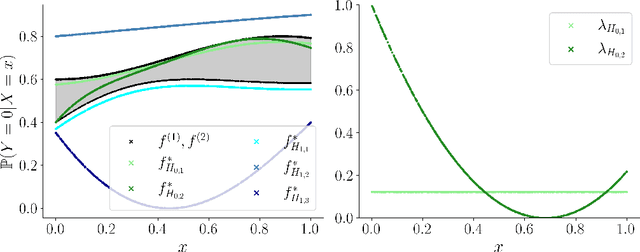

The accurate representation of epistemic uncertainty is a challenging yet essential task in machine learning. A widely used representation corresponds to convex sets of probabilistic predictors, also known as credal sets. One popular way of constructing these credal sets is via ensembling or specialized supervised learning methods, where the epistemic uncertainty can be quantified through measures such as the set size or the disagreement among members. In principle, these sets should contain the true data-generating distribution. As a necessary condition for this validity, we adopt the strongest notion of calibration as a proxy. Concretely, we propose a novel statistical test to determine whether there is a convex combination of the set's predictions that is calibrated in distribution. In contrast to previous methods, our framework allows the convex combination to be instance dependent, recognizing that different ensemble members may be better calibrated in different regions of the input space. Moreover, we learn this combination via proper scoring rules, which inherently optimize for calibration. Building on differentiable, kernel-based estimators of calibration errors, we introduce a nonparametric testing procedure and demonstrate the benefits of capturing instance-level variability on of synthetic and real-world experiments.
Is Epistemic Uncertainty Faithfully Represented by Evidential Deep Learning Methods?
Feb 20, 2024



Trustworthy ML systems should not only return accurate predictions, but also a reliable representation of their uncertainty. Bayesian methods are commonly used to quantify both aleatoric and epistemic uncertainty, but alternative approaches, such as evidential deep learning methods, have become popular in recent years. The latter group of methods in essence extends empirical risk minimization (ERM) for predicting second-order probability distributions over outcomes, from which measures of epistemic (and aleatoric) uncertainty can be extracted. This paper presents novel theoretical insights of evidential deep learning, highlighting the difficulties in optimizing second-order loss functions and interpreting the resulting epistemic uncertainty measures. With a systematic setup that covers a wide range of approaches for classification, regression and counts, it provides novel insights into issues of identifiability and convergence in second-order loss minimization, and the relative (rather than absolute) nature of epistemic uncertainty measures.