 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamHAN: IPv6 Address Correlation Attacks on TLS Encrypted Traffic via Siamese Heterogeneous Graph Attention Network
Apr 20, 2022

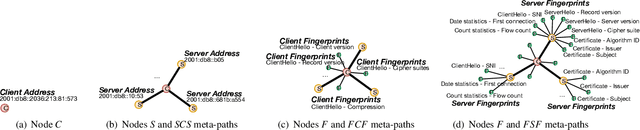

Unlike IPv4 addresses, which are typically masked by a NAT, IPv6 addresses could easily be correlated with user activity, endangering their privacy. Mitigations to address this privacy concern have been deployed, making existing approaches for address-to-user correlation unreliable. This work demonstrates that an adversary could still correlate IPv6 addresses with users accurately, even with these protection mechanisms. To do this, we propose an IPv6 address correlation model - SiamHAN. The model uses a Siamese Heterogeneous Graph Attention Network to measure whether two IPv6 client addresses belong to the same user even if the user's traffic is protected by TLS encryption. Using a large real-world dataset, we show that, for the tasks of tracking target users and discovering unique users, the state-of-the-art techniques could achieve only 85% and 60% accuracy, respectively. However, SiamHAN exhibits 99% and 88% accuracy.
MuKEA: Multimodal Knowledge Extraction and Accumulation for Knowledge-based Visual Question Answering
Mar 17, 2022

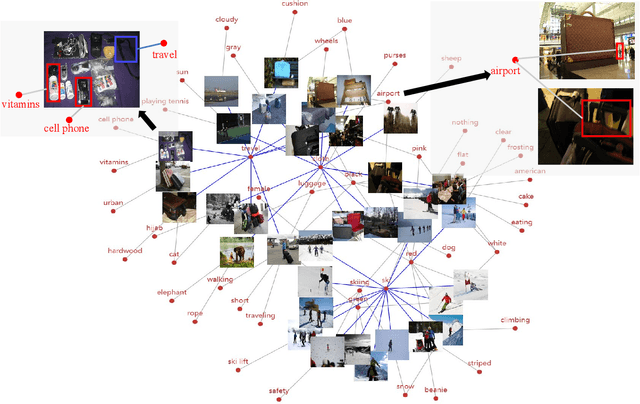
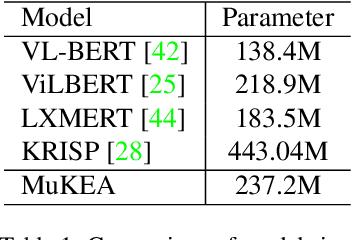
Knowledge-based visual question answering requires the ability of associating external knowledge for open-ended cross-modal scene understanding. One limitation of existing solutions is that they capture relevant knowledge from text-only knowledge bases, which merely contain facts expressed by first-order predicates or language descriptions while lacking complex but indispensable multimodal knowledge for visual understanding. How to construct vision-relevant and explainable multimodal knowledge for the VQA scenario has been less studied. In this paper, we propose MuKEA to represent multimodal knowledge by an explicit triplet to correlate visual objects and fact answers with implicit relations. To bridge the heterogeneous gap, we propose three objective losses to learn the triplet representations from complementary views: embedding structure, topological relation and semantic space. By adopting a pre-training and fine-tuning learning strategy, both basic and domain-specific multimodal knowledge are progressively accumulated for answer prediction. We outperform the state-of-the-art by 3.35% and 6.08% respectively on two challenging knowledge-required datasets: OK-VQA and KRVQA. Experimental results prove the complementary benefits of the multimodal knowledge with existing knowledge bases and the advantages of our end-to-end framework over the existing pipeline methods. The code is available at https://github.com/AndersonStra/MuKEA.