 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsset Harvester: Extracting 3D Assets from Autonomous Driving Logs for Simulation
Apr 20, 2026Closed-loop simulation is a core component of autonomous vehicle (AV) development, enabling scalable testing, training, and safety validation before real-world deployment. Neural scene reconstruction converts driving logs into interactive 3D environments for simulation, but it does not produce complete 3D object assets required for agent manipulation and large-viewpoint novel-view synthesis. To address this challenge, we present Asset Harvester, an image-to-3D model and end-to-end pipeline that converts sparse, in-the-wild object observations from real driving logs into complete, simulation-ready assets. Rather than relying on a single model component, we developed a system-level design for real-world AV data that combines large-scale curation of object-centric training tuples, geometry-aware preprocessing across heterogeneous sensors, and a robust training recipe that couples sparse-view-conditioned multiview generation with 3D Gaussian lifting. Within this system, SparseViewDiT is explicitly designed to address limited-angle views and other real-world data challenges. Together with hybrid data curation, augmentation, and self-distillation, this system enables scalable conversion of sparse AV object observations into reusable 3D assets.
Analyzing Quantization in TVM
Aug 19, 2023There has been many papers in academic literature on quantizing weight tensors in deep learning models to reduce inference latency and memory footprint. TVM also has the ability to quantize weights and support low-bit computations. Although quantization is typically expected to improve inference time, in TVM, the performance of 8-bit quantization does not meet the expectations. Typically, when applying 8-bit quantization to a deep learning model, it is usually expected to achieve around 50% of the full-precision inference time. However, in this particular case, not only does the quantized version fail to achieve the desired performance boost, but it actually performs worse, resulting in an inference time that is about 2 times as slow as the non-quantized version. In this project, we thoroughly investigate the reasons behind the underperformance and assess the compatibility and optimization opportunities of 8-bit quantization in TVM. We discuss the optimization of two different types of tasks: computation-bound and memory-bound, and provide a detailed comparison of various optimization techniques in TVM. Through the identification of performance issues, we have successfully improved quantization by addressing a bug in graph building. Furthermore, we analyze multiple optimization strategies to achieve the optimal quantization result. The best experiment achieves 163.88% improvement compared with the TVM compiled baseline in inference time for the compute-bound task and 194.98% for the memory-bound task.
UnrealNAS: Can We Search Neural Architectures with Unreal Data?
May 19, 2022
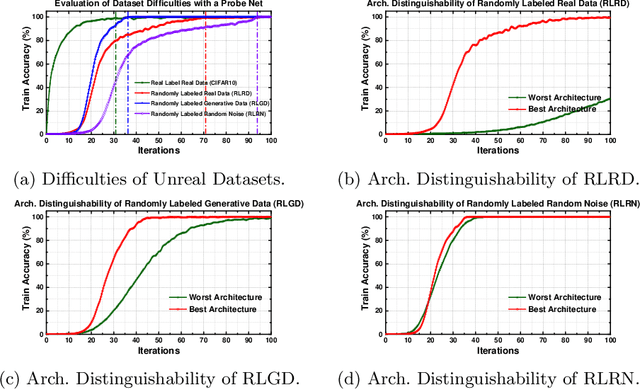
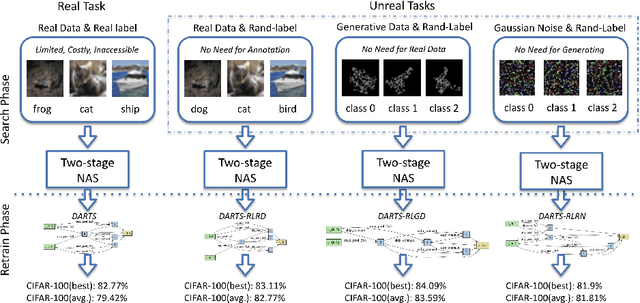
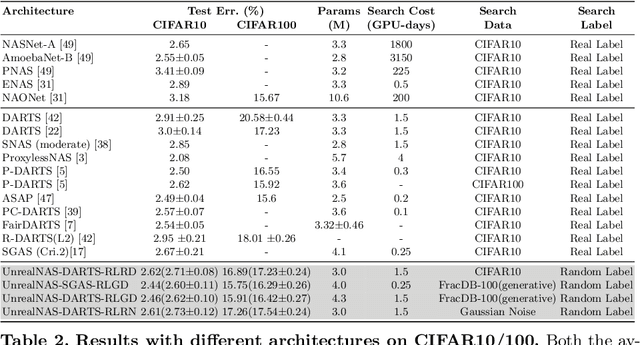
Neural architecture search (NAS) has shown great success in the automatic design of deep neural networks (DNNs). However, the best way to use data to search network architectures is still unclear and under exploration. Previous work has analyzed the necessity of having ground-truth labels in NAS and inspired broad interest. In this work, we take a further step to question whether real data is necessary for NAS to be effective. The answer to this question is important for applications with limited amount of accessible data, and can help people improve NAS by leveraging the extra flexibility of data generation. To explore if NAS needs real data, we construct three types of unreal datasets using: 1) randomly labeled real images; 2) generated images and labels; and 3) generated Gaussian noise with random labels. These datasets facilitate to analyze the generalization and expressivity of the searched architectures. We study the performance of architectures searched on these constructed datasets using popular differentiable NAS methods. Extensive experiments on CIFAR, ImageNet and CheXpert show that the searched architectures can achieve promising results compared with those derived from the conventional NAS pipeline with real labeled data, suggesting the feasibility of performing NAS with unreal data.
How does Truth Evolve into Fake News? An Empirical Study of Fake News Evolution
Mar 10, 2021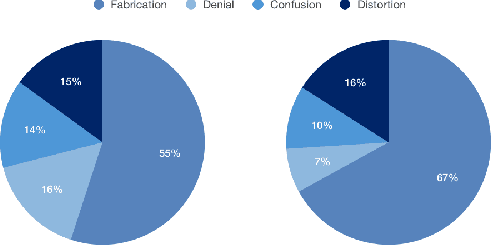
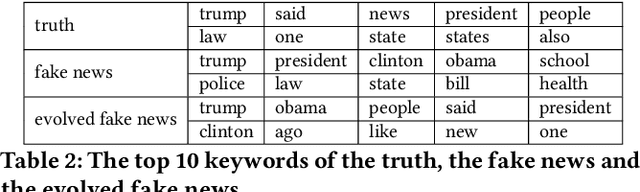
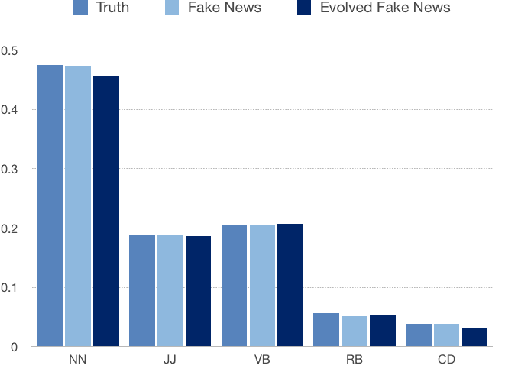
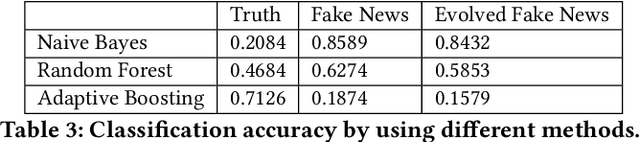
Automatically identifying fake news from the Internet is a challenging problem in deception detection tasks. Online news is modified constantly during its propagation, e.g., malicious users distort the original truth and make up fake news. However, the continuous evolution process would generate unprecedented fake news and cheat the original model. We present the Fake News Evolution (FNE) dataset: a new dataset tracking the fake news evolution process. Our dataset is composed of 950 paired data, each of which consists of articles representing the three significant phases of the evolution process, which are the truth, the fake news, and the evolved fake news. We observe the features during the evolution and they are the disinformation techniques, text similarity, top 10 keywords, classification accuracy, parts of speech, and sentiment properties.
* 5 pages, 2 figures