 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-decision Regression between Shortest Path and Minimum Steiner Tree
Feb 03, 2024



Considering a graph with unknown weights, can we find the shortest path for a pair of nodes if we know the minimal Steiner trees associated with some subset of nodes? That is, with respect to a fixed latent decision-making system (e.g., a weighted graph), we seek to solve one optimization problem (e.g., the shortest path problem) by leveraging information associated with another optimization problem (e.g., the minimal Steiner tree problem). In this paper, we study such a prototype problem called \textit{query-decision regression with task shifts}, focusing on the shortest path problem and the minimum Steiner tree problem. We provide theoretical insights regarding the design of realizable hypothesis spaces for building scoring models, and present two principled learning frameworks. Our experimental studies show that such problems can be solved to a decent extent with statistical significance.
VN-Solver: Vision-based Neural Solver for Combinatorial Optimization over Graphs
Aug 06, 2023



Data-driven approaches have been proven effective in solving combinatorial optimization problems over graphs such as the traveling salesman problems and the vehicle routing problem. The rationale behind such methods is that the input instances may follow distributions with salient patterns that can be leveraged to overcome the worst-case computational hardness. For optimization problems over graphs, the common practice of neural combinatorial solvers consumes the inputs in the form of adjacency matrices. In this paper, we explore a vision-based method that is conceptually novel: can neural models solve graph optimization problems by \textit{taking a look at the graph pattern}? Our results suggest that the performance of such vision-based methods is not only non-trivial but also comparable to the state-of-the-art matrix-based methods, which opens a new avenue for developing data-driven optimization solvers.
Graph-based Semantical Extractive Text Analysis
Dec 19, 2022


In the past few decades, there has been an explosion in the amount of available data produced from various sources with different topics. The availability of this enormous data necessitates us to adopt effective computational tools to explore the data. This leads to an intense growing interest in the research community to develop computational methods focused on processing this text data. A line of study focused on condensing the text so that we are able to get a higher level of understanding in a shorter time. The two important tasks to do this are keyword extraction and text summarization. In keyword extraction, we are interested in finding the key important words from a text. This makes us familiar with the general topic of a text. In text summarization, we are interested in producing a short-length text which includes important information about the document. The TextRank algorithm, an unsupervised learning method that is an extension of the PageRank (algorithm which is the base algorithm of Google search engine for searching pages and ranking them) has shown its efficacy in large-scale text mining, especially for text summarization and keyword extraction. this algorithm can automatically extract the important parts of a text (keywords or sentences) and declare them as the result. However, this algorithm neglects the semantic similarity between the different parts. In this work, we improved the results of the TextRank algorithm by incorporating the semantic similarity between parts of the text. Aside from keyword extraction and text summarization, we develop a topic clustering algorithm based on our framework which can be used individually or as a part of generating the summary to overcome coverage problems.
Identifying the Leading Factors of Significant Weight Gains Using a New Rule Discovery Method
Nov 04, 2021
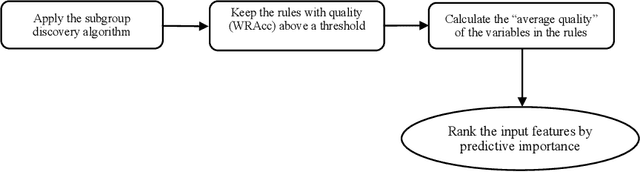
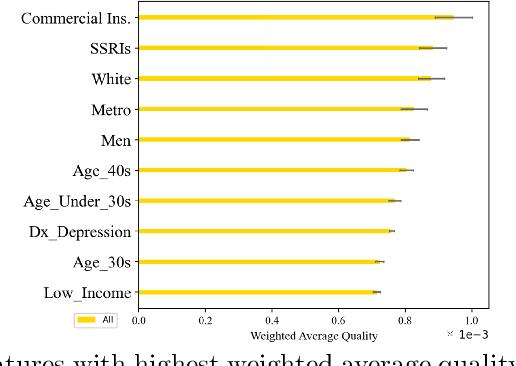

Overweight and obesity remain a major global public health concern and identifying the individualized patterns that increase the risk of future weight gains has a crucial role in preventing obesity and numerous sub-sequent diseases associated with obesity. In this work, we use a rule discovery method to study this problem, by presenting an approach that offers genuine interpretability and concurrently optimizes the accuracy(being correct often) and support (applying to many samples) of the identified patterns. Specifically, we extend an established subgroup-discovery method to generate the desired rules of type X -> Y and show how top features can be extracted from the X side, functioning as the best predictors of Y. In our obesity problem, X refers to the extracted features from very large and multi-site EHR data, and Y indicates significant weight gains. Using our method, we also extensively compare the differences and inequities in patterns across 22 strata determined by the individual's gender, age, race, insurance type, neighborhood type, and income level. Through extensive series of experiments, we show new and complementary findings regarding the predictors of future dangerous weight gains.