 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying the Risks of Chronic Diseases Using BMI Trajectories
Nov 09, 2021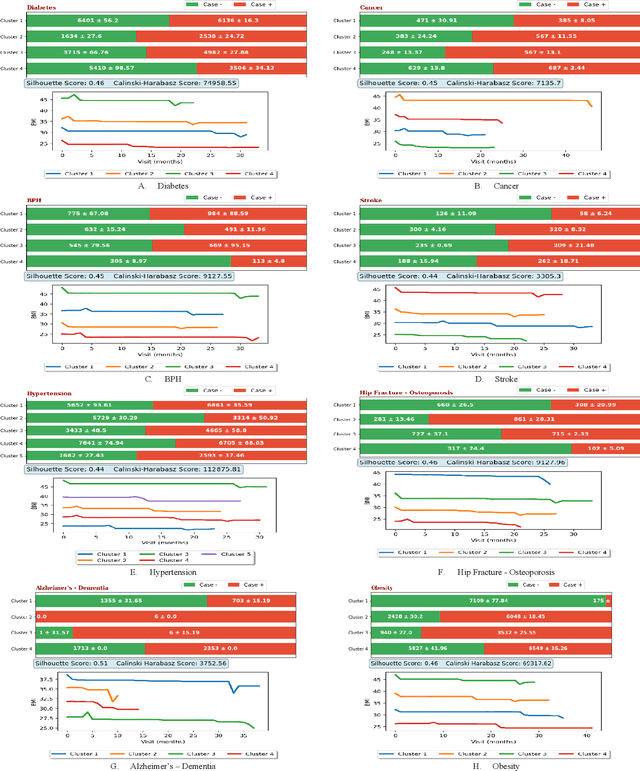
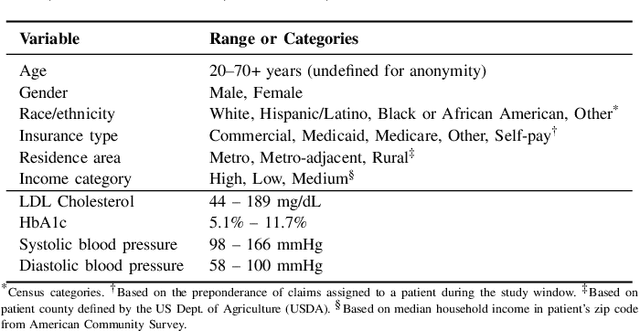
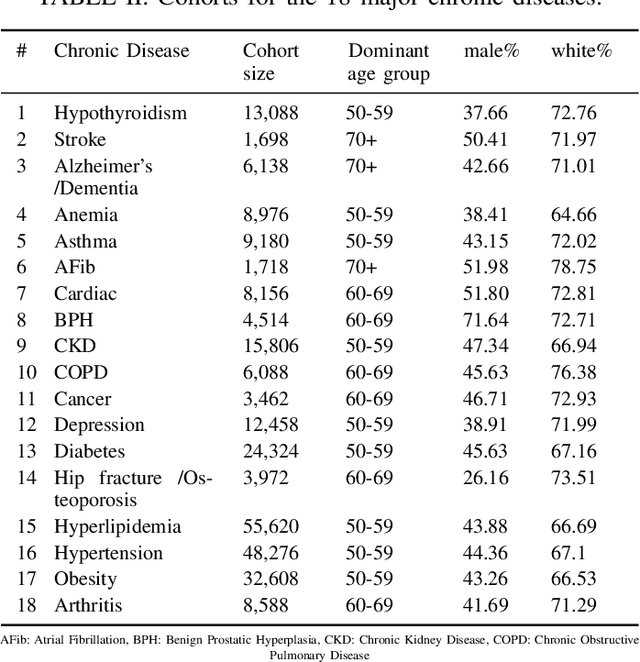
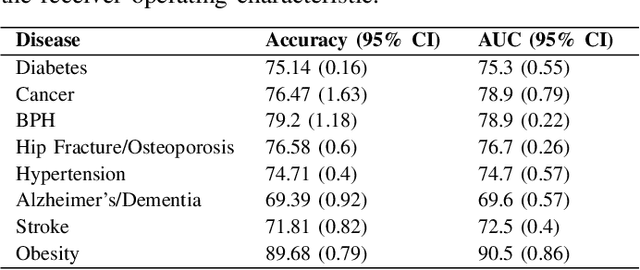
Obesity is a major health problem, increasing the risk of various major chronic diseases, such as diabetes, cancer, and stroke. While the role of obesity identified by cross-sectional BMI recordings has been heavily studied, the role of BMI trajectories is much less explored. In this study, we use a machine learning approach to subtype individuals' risk of developing 18 major chronic diseases by using their BMI trajectories extracted from a large and geographically diverse EHR dataset capturing the health status of around two million individuals for a period of six years. We define nine new interpretable and evidence-based variables based on the BMI trajectories to cluster the patients into subgroups using the k-means clustering method. We thoroughly review each clusters' characteristics in terms of demographic, socioeconomic, and physiological measurement variables to specify the distinct properties of the patients in the clusters. In our experiments, direct relationship of obesity with diabetes, hypertension, Alzheimer's, and dementia have been re-established and distinct clusters with specific characteristics for several of the chronic diseases have been found to be conforming or complementary to the existing body of knowledge.
Identifying the Leading Factors of Significant Weight Gains Using a New Rule Discovery Method
Nov 04, 2021
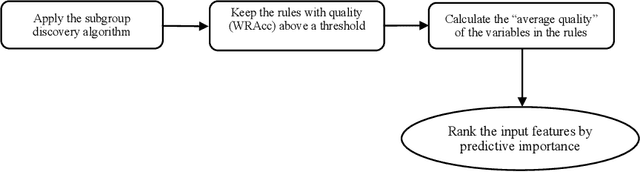
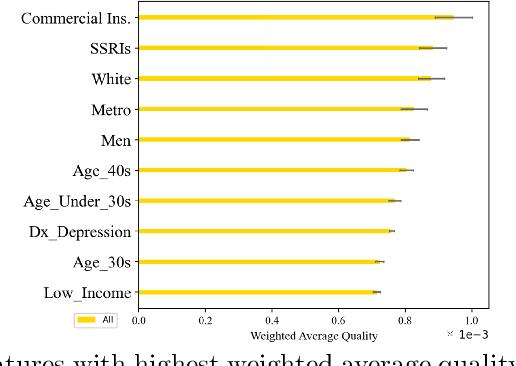

Overweight and obesity remain a major global public health concern and identifying the individualized patterns that increase the risk of future weight gains has a crucial role in preventing obesity and numerous sub-sequent diseases associated with obesity. In this work, we use a rule discovery method to study this problem, by presenting an approach that offers genuine interpretability and concurrently optimizes the accuracy(being correct often) and support (applying to many samples) of the identified patterns. Specifically, we extend an established subgroup-discovery method to generate the desired rules of type X -> Y and show how top features can be extracted from the X side, functioning as the best predictors of Y. In our obesity problem, X refers to the extracted features from very large and multi-site EHR data, and Y indicates significant weight gains. Using our method, we also extensively compare the differences and inequities in patterns across 22 strata determined by the individual's gender, age, race, insurance type, neighborhood type, and income level. Through extensive series of experiments, we show new and complementary findings regarding the predictors of future dangerous weight gains.