 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Physics and Data-Driven Approaches: An Explainable and Uncertainty-Aware Hybrid Model for Wind Turbine Power Prediction
Feb 11, 2025
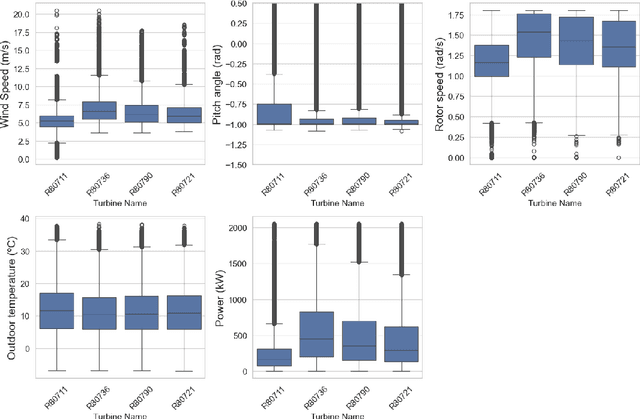
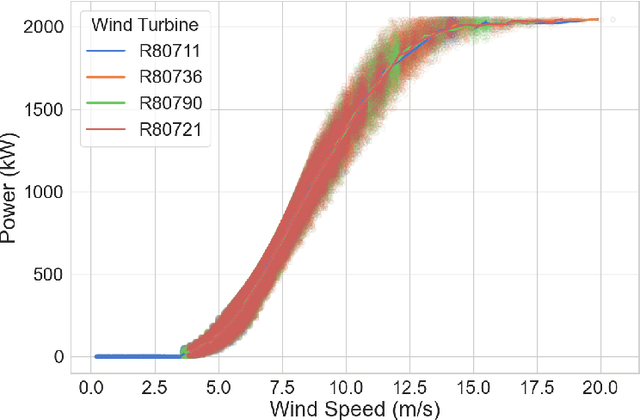

The rapid growth of the wind energy sector underscores the urgent need to optimize turbine operations and ensure effective maintenance through early fault detection systems. While traditional empirical and physics-based models offer approximate predictions of power generation based on wind speed, they often fail to capture the complex, non-linear relationships between other input variables and the resulting power output. Data-driven machine learning methods present a promising avenue for improving wind turbine modeling by leveraging large datasets, enhancing prediction accuracy but often at the cost of interpretability. In this study, we propose a hybrid semi-parametric model that combines the strengths of both approaches, applied to a dataset from a wind farm with four turbines. The model integrates a physics-inspired submodel, providing a reasonable approximation of power generation, with a non-parametric submodel that predicts the residuals. This non-parametric submodel is trained on a broader range of variables to account for phenomena not captured by the physics-based component. The hybrid model achieves a 37% improvement in prediction accuracy over the physics-based model. To enhance interpretability, SHAP values are used to analyze the influence of input features on the residual submodel's output. Additionally, prediction uncertainties are quantified using a conformalized quantile regression method. The combination of these techniques, alongside the physics grounding of the parametric submodel, provides a flexible, accurate, and reliable framework. Ultimately, this study opens the door for evaluating the impact of unmodeled variables on wind turbine power generation, offering a basis for potential optimization.
SINERGYM -- A virtual testbed for building energy optimization with Reinforcement Learning
Dec 11, 2024



Simulation has become a crucial tool for Building Energy Optimization (BEO) as it enables the evaluation of different design and control strategies at a low cost. Machine Learning (ML) algorithms can leverage large-scale simulations to learn optimal control from vast amounts of data without supervision, particularly under the Reinforcement Learning (RL) paradigm. Unfortunately, the lack of open and standardized tools has hindered the widespread application of ML and RL to BEO. To address this issue, this paper presents Sinergym, an open-source Python-based virtual testbed for large-scale building simulation, data collection, continuous control, and experiment monitoring. Sinergym provides a consistent interface for training and running controllers, predefined benchmarks, experiment visualization and replication support, and comprehensive documentation in a ready-to-use software library. This paper 1) highlights the main features of Sinergym in comparison to other existing frameworks, 2) describes its basic usage, and 3) demonstrates its applicability for RL-based BEO through several representative examples. By integrating simulation, data, and control, Sinergym supports the development of intelligent, data-driven applications for more efficient and responsive building operations, aligning with the objectives of digital twin technology.
An experimental evaluation of Deep Reinforcement Learning algorithms for HVAC control
Jan 11, 2024Heating, Ventilation, and Air Conditioning (HVAC) systems are a major driver of energy consumption in commercial and residential buildings. Recent studies have shown that Deep Reinforcement Learning (DRL) algorithms can outperform traditional reactive controllers. However, DRL-based solutions are generally designed for ad hoc setups and lack standardization for comparison. To fill this gap, this paper provides a critical and reproducible evaluation, in terms of comfort and energy consumption, of several state-of-the-art DRL algorithms for HVAC control. The study examines the controllers' robustness, adaptability, and trade-off between optimization goals by using the Sinergym framework. The results obtained confirm the potential of DRL algorithms, such as SAC and TD3, in complex scenarios and reveal several challenges related to generalization and incremental learning.
Prediction of wind turbines power with physics-informed neural networks and evidential uncertainty quantification
Jul 27, 2023The ever-growing use of wind energy makes necessary the optimization of turbine operations through pitch angle controllers and their maintenance with early fault detection. It is crucial to have accurate and robust models imitating the behavior of wind turbines, especially to predict the generated power as a function of the wind speed. Existing empirical and physics-based models have limitations in capturing the complex relations between the input variables and the power, aggravated by wind variability. Data-driven methods offer new opportunities to enhance wind turbine modeling of large datasets by improving accuracy and efficiency. In this study, we used physics-informed neural networks to reproduce historical data coming from 4 turbines in a wind farm, while imposing certain physical constraints to the model. The developed models for regression of the power, torque, and power coefficient as output variables showed great accuracy for both real data and physical equations governing the system. Lastly, introducing an efficient evidential layer provided uncertainty estimations of the predictions, proved to be consistent with the absolute error, and made possible the definition of a confidence interval in the power curve.
Attention-based Convolutional Autoencoders for 3D-Variational Data Assimilation
Jan 06, 2021
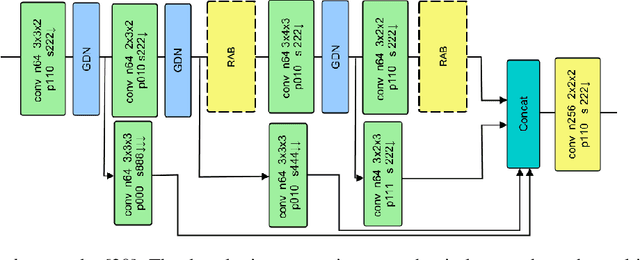


We propose a new 'Bi-Reduced Space' approach to solving 3D Variational Data Assimilation using Convolutional Autoencoders. We prove that our approach has the same solution as previous methods but has significantly lower computational complexity; in other words, we reduce the computational cost without affecting the data assimilation accuracy. We tested the new method with data from a real-world application: a pollution model of a site in Elephant and Castle, London and found that we could reduce the size of the background covariance matrix representation by O(10^3) and, at the same time, increase our data assimilation accuracy with respect to existing reduced space methods.
* Published in Computer Methods in Applied Mechanics and Engineering in Dec 2020
Characterizing Political Fake News in Twitter by its Meta-Data
Dec 16, 2017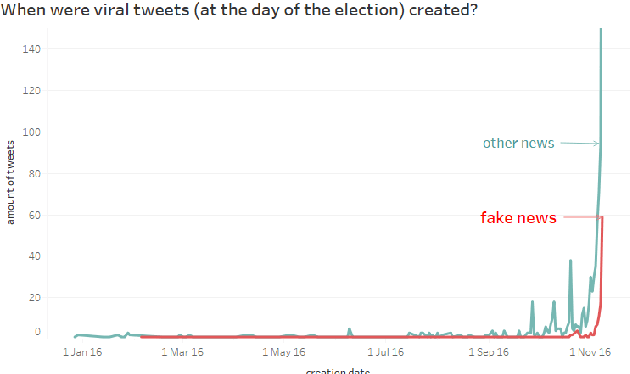
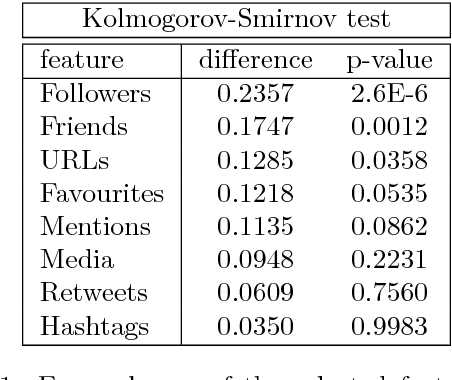
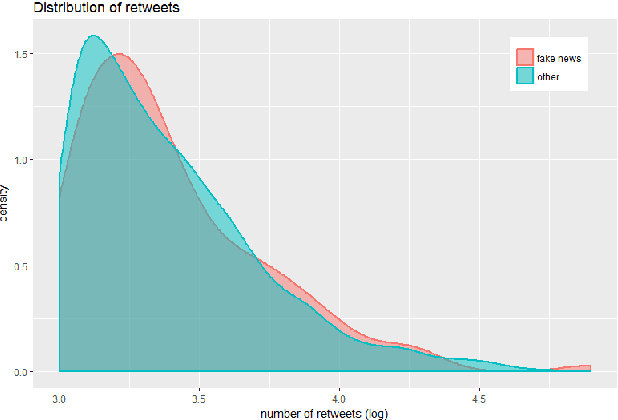

This article presents a preliminary approach towards characterizing political fake news on Twitter through the analysis of their meta-data. In particular, we focus on more than 1.5M tweets collected on the day of the election of Donald Trump as 45th president of the United States of America. We use the meta-data embedded within those tweets in order to look for differences between tweets containing fake news and tweets not containing them. Specifically, we perform our analysis only on tweets that went viral, by studying proxies for users' exposure to the tweets, by characterizing accounts spreading fake news, and by looking at their polarization. We found significant differences on the distribution of followers, the number of URLs on tweets, and the verification of the users.