 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Convolutional Autoencoders for 3D-Variational Data Assimilation
Jan 06, 2021


We propose a new 'Bi-Reduced Space' approach to solving 3D Variational Data Assimilation using Convolutional Autoencoders. We prove that our approach has the same solution as previous methods but has significantly lower computational complexity; in other words, we reduce the computational cost without affecting the data assimilation accuracy. We tested the new method with data from a real-world application: a pollution model of a site in Elephant and Castle, London and found that we could reduce the size of the background covariance matrix representation by O(10^3) and, at the same time, increase our data assimilation accuracy with respect to existing reduced space methods.
* Published in Computer Methods in Applied Mechanics and Engineering in Dec 2020
Empirical Evaluation of Deep Learning Model Compression Techniques on the WaveNet Vocoder
Nov 20, 2020
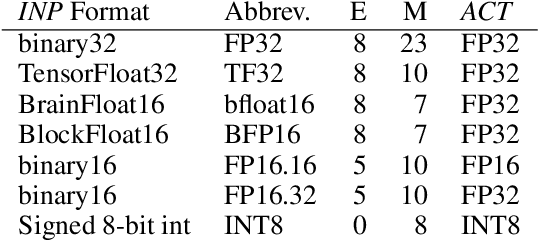
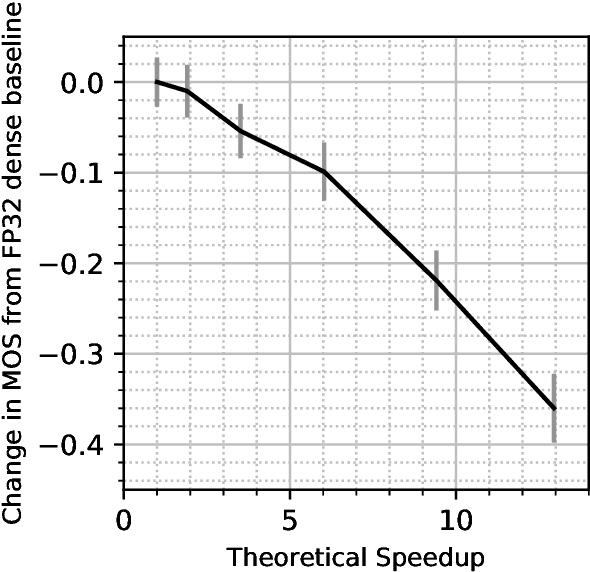
WaveNet is a state-of-the-art text-to-speech vocoder that remains challenging to deploy due to its autoregressive loop. In this work we focus on ways to accelerate the original WaveNet architecture directly, as opposed to modifying the architecture, such that the model can be deployed as part of a scalable text-to-speech system. We survey a wide variety of model compression techniques that are amenable to deployment on a range of hardware platforms. In particular, we compare different model sparsity methods and levels, and seven widely used precisions as targets for quantization; and are able to achieve models with a compression ratio of up to 13.84 without loss in audio fidelity compared to a dense, single-precision floating-point baseline. All techniques are implemented using existing open source deep learning frameworks and libraries to encourage their wider adoption.