 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut of Context: Investigating the Bias and Fairness Concerns of "Artificial Intelligence as a Service"
Feb 02, 2023"AI as a Service" (AIaaS) is a rapidly growing market, offering various plug-and-play AI services and tools. AIaaS enables its customers (users) - who may lack the expertise, data, and/or resources to develop their own systems - to easily build and integrate AI capabilities into their applications. Yet, it is known that AI systems can encapsulate biases and inequalities that can have societal impact. This paper argues that the context-sensitive nature of fairness is often incompatible with AIaaS' 'one-size-fits-all' approach, leading to issues and tensions. Specifically, we review and systematise the AIaaS space by proposing a taxonomy of AI services based on the levels of autonomy afforded to the user. We then critically examine the different categories of AIaaS, outlining how these services can lead to biases or be otherwise harmful in the context of end-user applications. In doing so, we seek to draw research attention to the challenges of this emerging area.
Exploring How Machine Learning Practitioners (Try To) Use Fairness Toolkits
May 13, 2022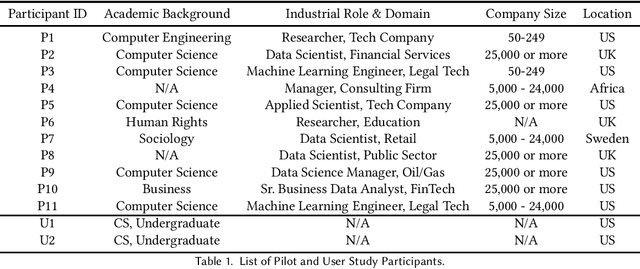
Recent years have seen the development of many open-source ML fairness toolkits aimed at helping ML practitioners assess and address unfairness in their systems. However, there has been little research investigating how ML practitioners actually use these toolkits in practice. In this paper, we conducted the first in-depth empirical exploration of how industry practitioners (try to) work with existing fairness toolkits. In particular, we conducted think-aloud interviews to understand how participants learn about and use fairness toolkits, and explored the generality of our findings through an anonymous online survey. We identified several opportunities for fairness toolkits to better address practitioner needs and scaffold them in using toolkits effectively and responsibly. Based on these findings, we highlight implications for the design of future open-source fairness toolkits that can support practitioners in better contextualizing, communicating, and collaborating around ML fairness efforts.
Reviewable Automated Decision-Making: A Framework for Accountable Algorithmic Systems
Feb 10, 2021
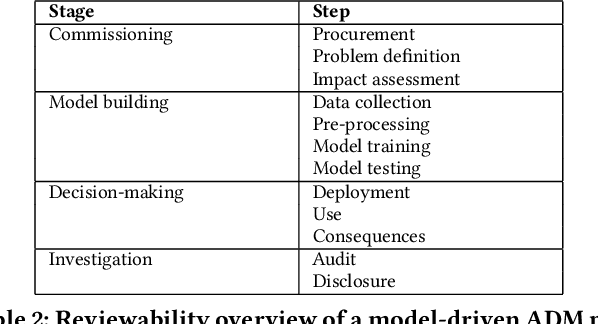
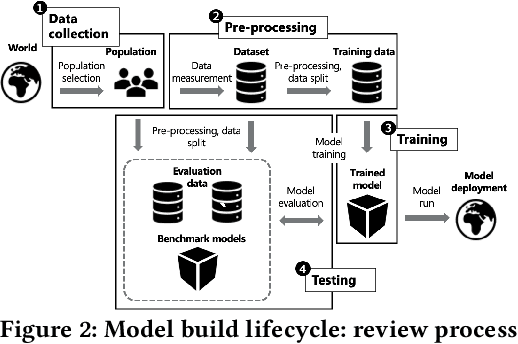
This paper introduces reviewability as a framework for improving the accountability of automated and algorithmic decision-making (ADM) involving machine learning. We draw on an understanding of ADM as a socio-technical process involving both human and technical elements, beginning before a decision is made and extending beyond the decision itself. While explanations and other model-centric mechanisms may assist some accountability concerns, they often provide insufficient information of these broader ADM processes for regulatory oversight and assessments of legal compliance. Reviewability involves breaking down the ADM process into technical and organisational elements to provide a systematic framework for determining the contextually appropriate record-keeping mechanisms to facilitate meaningful review - both of individual decisions and of the process as a whole. We argue that a reviewability framework, drawing on administrative law's approach to reviewing human decision-making, offers a practical way forward towards more a more holistic and legally-relevant form of accountability for ADM.