 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Examples in Constrained Domains
Nov 02, 2020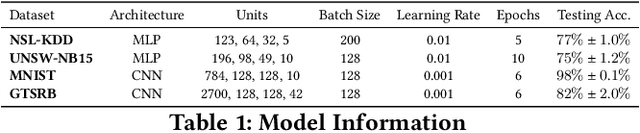

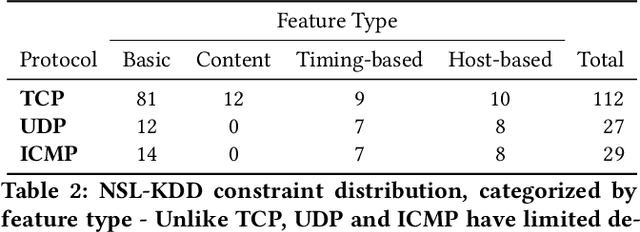
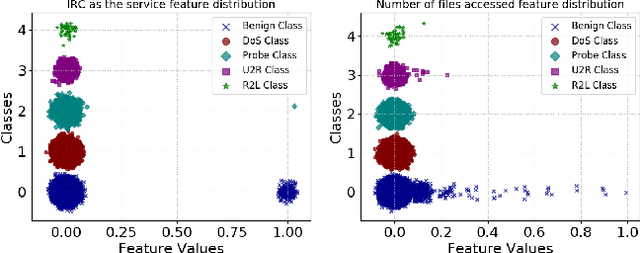
Machine learning algorithms have been shown to be vulnerable to adversarial manipulation through systematic modification of inputs (e.g., adversarial examples) in domains such as image recognition. Under the default threat model, the adversary exploits the unconstrained nature of images; each feature (pixel) is fully under control of the adversary. However, it is not clear how these attacks translate to constrained domains that limit which and how features can be modified by the adversary (e.g., network intrusion detection). In this paper, we explore whether constrained domains are less vulnerable than unconstrained domains to adversarial example generation algorithms. We create an algorithm for generating adversarial sketches: targeted universal perturbation vectors which encode feature saliency within the envelope of domain constraints. To assess how these algorithms perform, we evaluate them in constrained (e.g., network intrusion detection) and unconstrained (e.g., image recognition) domains. The results demonstrate that our approaches generate misclassification rates in constrained domains that were comparable to those of unconstrained domains (greater than 95%). Our investigation shows that the narrow attack surface exposed by constrained domains is still sufficiently large to craft successful adversarial examples; and thus, constraints do not appear to make a domain robust. Indeed, with as little as five randomly selected features, one can still generate adversarial examples.