 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCleanGraph: Human-in-the-loop Knowledge Graph Refinement and Completion
May 08, 2024



This paper presents CleanGraph, an interactive web-based tool designed to facilitate the refinement and completion of knowledge graphs. Maintaining the reliability of knowledge graphs, which are grounded in high-quality and error-free facts, is crucial for real-world applications such as question-answering and information retrieval systems. These graphs are often automatically assembled from textual sources by extracting semantic triples via information extraction. However, assuring the quality of these extracted triples, especially when dealing with large or low-quality datasets, can pose a significant challenge and adversely affect the performance of downstream applications. CleanGraph allows users to perform Create, Read, Update, and Delete (CRUD) operations on their graphs, as well as apply models in the form of plugins for graph refinement and completion tasks. These functionalities enable users to enhance the integrity and reliability of their graph data. A demonstration of CleanGraph and its source code can be accessed at https://github.com/nlp-tlp/CleanGraph under the MIT License.
Large Language Models for Failure Mode Classification: An Investigation
Sep 15, 2023
In this paper we present the first investigation into the effectiveness of Large Language Models (LLMs) for Failure Mode Classification (FMC). FMC, the task of automatically labelling an observation with a corresponding failure mode code, is a critical task in the maintenance domain as it reduces the need for reliability engineers to spend their time manually analysing work orders. We detail our approach to prompt engineering to enable an LLM to predict the failure mode of a given observation using a restricted code list. We demonstrate that the performance of a GPT-3.5 model (F1=0.80) fine-tuned on annotated data is a significant improvement over a currently available text classification model (F1=0.60) trained on the same annotated data set. The fine-tuned model also outperforms the out-of-the box GPT-3.5 (F1=0.46). This investigation reinforces the need for high quality fine-tuning data sets for domain-specific tasks using LLMs.
E2EET: From Pipeline to End-to-end Entity Typing via Transformer-Based Embeddings
Mar 23, 2020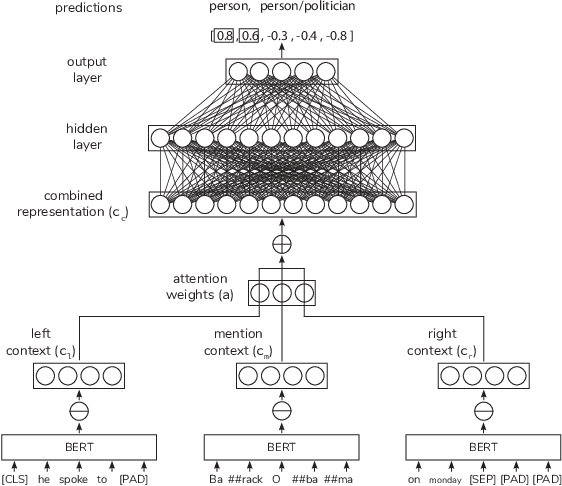
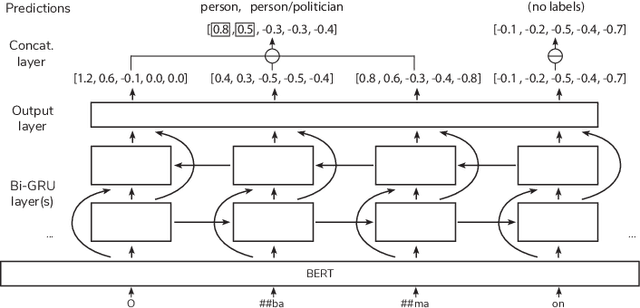
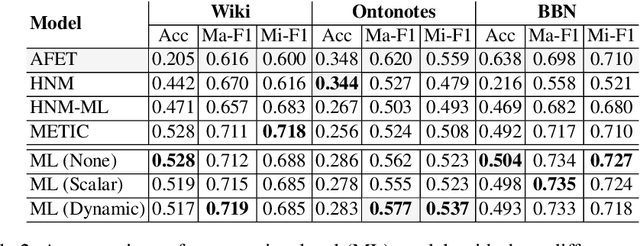
Entity Typing (ET) is the process of identifying the semantic types of every entity within a corpus. In contrast to Named Entity Recognition, where each token in a sentence is labelled with zero or one class label, ET involves labelling each entity mention with one or more class labels. Existing entity typing models, which operate at the mention level, are limited by two key factors: they do not make use of recently-proposed context-dependent embeddings, and are trained on fixed context windows. They are therefore sensitive to window size selection and are unable to incorporate the context of the entire document. In light of these drawbacks we propose to incorporate context using transformer-based embeddings for a mention-level model, and an end-to-end model using a Bi-GRU to remove the dependency on window size. An extensive ablative study demonstrates the effectiveness of contextualised embeddings for mention-level models and the competitiveness of our end-to-end model for entity typing.
Word-level Lexical Normalisation using Context-Dependent Embeddings
Nov 13, 2019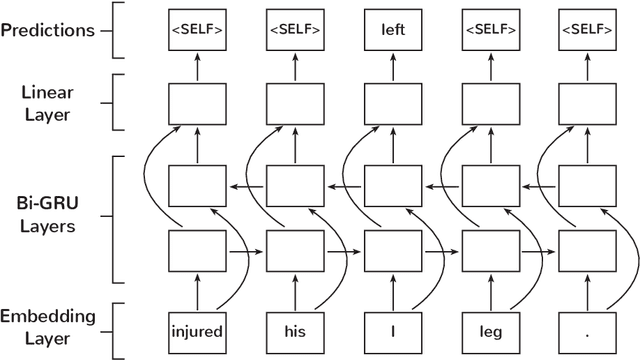



Lexical normalisation (LN) is the process of correcting each word in a dataset to its canonical form so that it may be more easily and more accurately analysed. Most lexical normalisation systems operate at the character-level, while word-level models are seldom used. Recent language models offer solutions to the drawbacks of word-level LN models, yet, to the best of our knowledge, no research has investigated their effectiveness on LN. In this paper we introduce a word-level GRU-based LN model and investigate the effectiveness of recent embedding techniques on word-level LN. Our results show that our GRU-based word-level model produces greater results than character-level models, and outperforms existing deep-learning based LN techniques on Twitter data. We also find that randomly-initialised embeddings are capable of outperforming pre-trained embedding models in certain scenarios. Finally, we release a substantial lexical normalisation dataset to the community.
ICDM 2019 Knowledge Graph Contest: Team UWA
Sep 04, 2019


We present an overview of our triple extraction system for the ICDM 2019 Knowledge Graph Contest. Our system uses a pipeline-based approach to extract a set of triples from a given document. It offers a simple and effective solution to the challenge of knowledge graph construction from domain-specific text. It also provides the facility to visualise useful information about each triple such as the degree, betweenness, structured relation type(s), and named entity types.
Natural Language Feature Selection via Cooccurrence
Mar 08, 2014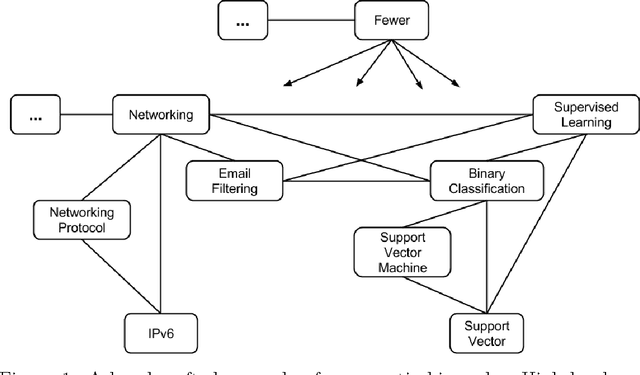
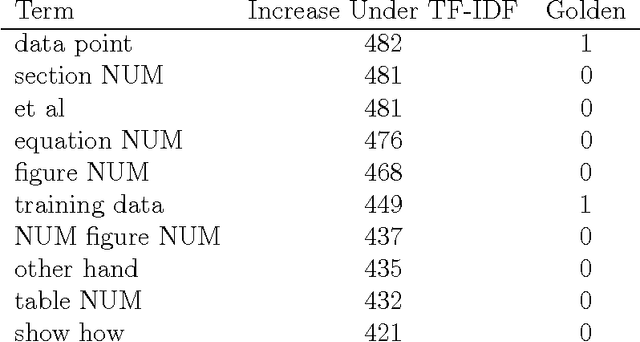
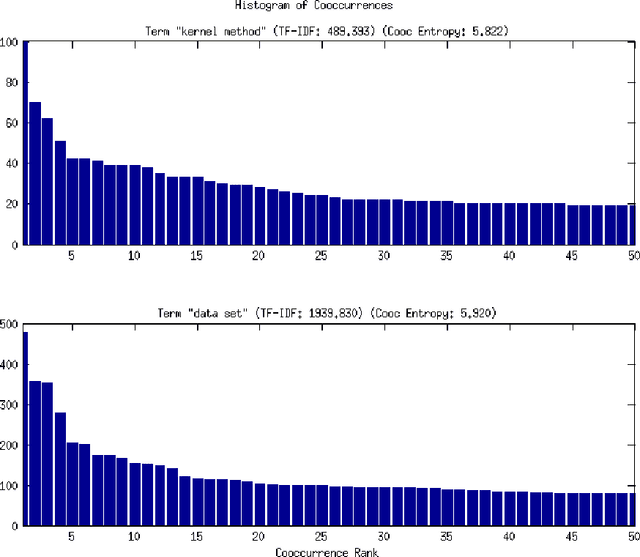
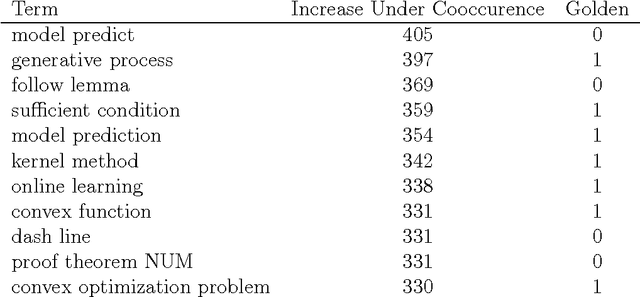
Specificity is important for extracting collocations, keyphrases, multi-word and index terms [Newman et al. 2012]. It is also useful for tagging, ontology construction [Ryu and Choi 2006], and automatic summarization of documents [Louis and Nenkova 2011, Chali and Hassan 2012]. Term frequency and inverse-document frequency (TF-IDF) are typically used to do this, but fail to take advantage of the semantic relationships between terms [Church and Gale 1995]. The result is that general idiomatic terms are mistaken for specific terms. We demonstrate use of relational data for estimation of term specificity. The specificity of a term can be learned from its distribution of relations with other terms. This technique is useful for identifying relevant words or terms for other natural language processing tasks.