 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord-level Lexical Normalisation using Context-Dependent Embeddings
Nov 13, 2019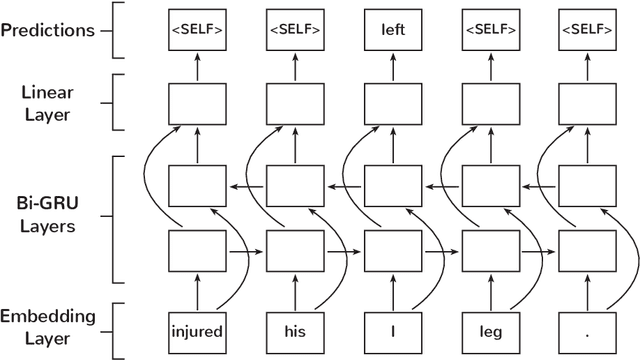



Lexical normalisation (LN) is the process of correcting each word in a dataset to its canonical form so that it may be more easily and more accurately analysed. Most lexical normalisation systems operate at the character-level, while word-level models are seldom used. Recent language models offer solutions to the drawbacks of word-level LN models, yet, to the best of our knowledge, no research has investigated their effectiveness on LN. In this paper we introduce a word-level GRU-based LN model and investigate the effectiveness of recent embedding techniques on word-level LN. Our results show that our GRU-based word-level model produces greater results than character-level models, and outperforms existing deep-learning based LN techniques on Twitter data. We also find that randomly-initialised embeddings are capable of outperforming pre-trained embedding models in certain scenarios. Finally, we release a substantial lexical normalisation dataset to the community.