Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICDM 2019 Knowledge Graph Contest: Team UWA
Paper and Code



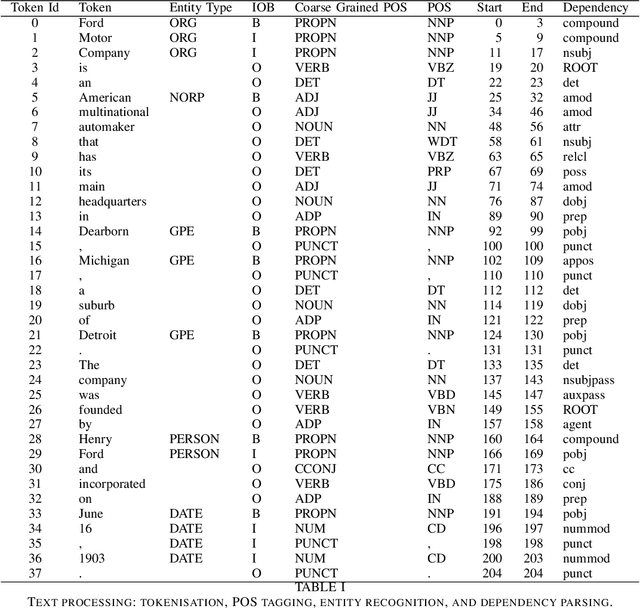
We present an overview of our triple extraction system for the ICDM 2019 Knowledge Graph Contest. Our system uses a pipeline-based approach to extract a set of triples from a given document. It offers a simple and effective solution to the challenge of knowledge graph construction from domain-specific text. It also provides the facility to visualise useful information about each triple such as the degree, betweenness, structured relation type(s), and named entity types.
View paper on