 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Feature Selection via Cooccurrence
Paper and Code
Mar 08, 2014
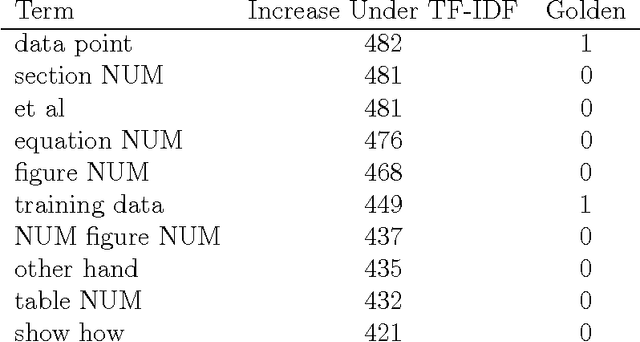
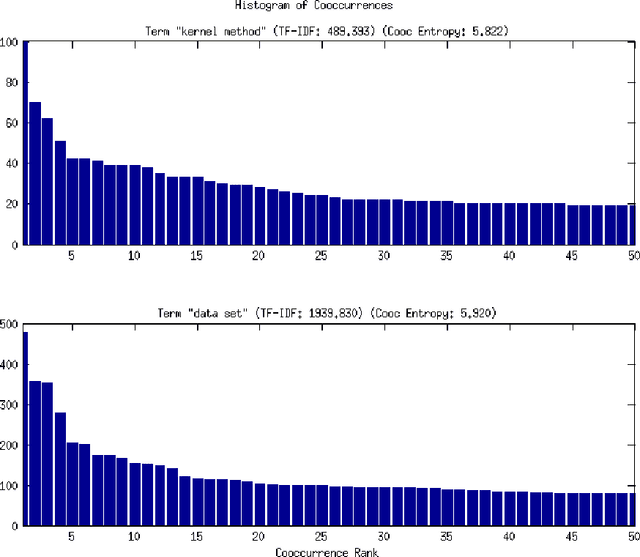
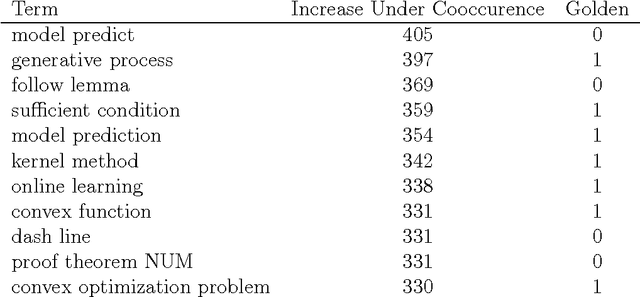
Specificity is important for extracting collocations, keyphrases, multi-word and index terms [Newman et al. 2012]. It is also useful for tagging, ontology construction [Ryu and Choi 2006], and automatic summarization of documents [Louis and Nenkova 2011, Chali and Hassan 2012]. Term frequency and inverse-document frequency (TF-IDF) are typically used to do this, but fail to take advantage of the semantic relationships between terms [Church and Gale 1995]. The result is that general idiomatic terms are mistaken for specific terms. We demonstrate use of relational data for estimation of term specificity. The specificity of a term can be learned from its distribution of relations with other terms. This technique is useful for identifying relevant words or terms for other natural language processing tasks.