 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Interference: Removing Interference Bias in Semi-Parametric Causal Models
Mar 24, 2025Interference bias is a major impediment to identifying causal effects in real-world settings. For example, vaccination reduces the transmission of a virus in a population such that everyone benefits -- even those who are not treated. This is a source of bias that must be accounted for if one wants to learn the true effect of a vaccine on an individual's immune system. Previous approaches addressing interference bias require strong domain knowledge in the form of a graphical interaction network fully describing interference between units. Moreover, they place additional constraints on the form the interference can take, such as restricting to linear outcome models, and assuming that interference experienced by a unit does not depend on the unit's covariates. Our work addresses these shortcomings. We first provide and justify a novel definition of causal models with local interference. We prove that the True Average Causal Effect, a measure of causality where interference has been removed, can be identified in certain semi-parametric models satisfying this definition. These models allow for non-linearity, and also for interference to depend on a unit's covariates. An analytic estimand for the True Average Causal Effect is given in such settings. We further prove that the True Average Causal Effect cannot be identified in arbitrary models with local interference, showing that identification requires semi-parametric assumptions. Finally, we provide an empirical validation of our method on both simulated and real-world datasets.
The Hardness of Validating Observational Studies with Experimental Data
Mar 19, 2025Observational data is often readily available in large quantities, but can lead to biased causal effect estimates due to the presence of unobserved confounding. Recent works attempt to remove this bias by supplementing observational data with experimental data, which, when available, is typically on a smaller scale due to the time and cost involved in running a randomised controlled trial. In this work, we prove a theorem that places fundamental limits on this ``best of both worlds'' approach. Using the framework of impossible inference, we show that although it is possible to use experimental data to \emph{falsify} causal effect estimates from observational data, in general it is not possible to \emph{validate} such estimates. Our theorem proves that while experimental data can be used to detect bias in observational studies, without additional assumptions on the smoothness of the correction function, it can not be used to remove it. We provide a practical example of such an assumption, developing a novel Gaussian Process based approach to construct intervals which contain the true treatment effect with high probability, both inside and outside of the support of the experimental data. We demonstrate our methodology on both simulated and semi-synthetic datasets and make the \href{https://github.com/Jakefawkes/Obs_and_exp_data}{code available}.
Contrastive representations of high-dimensional, structured treatments
Nov 28, 2024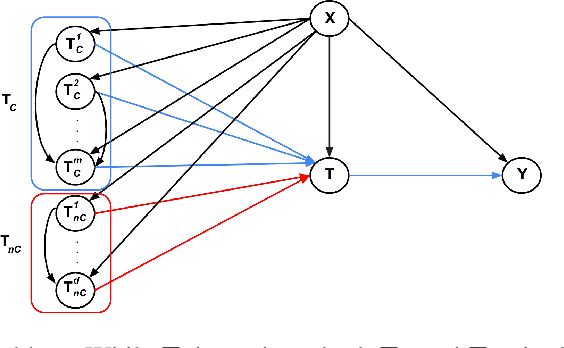



Estimating causal effects is vital for decision making. In standard causal effect estimation, treatments are usually binary- or continuous-valued. However, in many important real-world settings, treatments can be structured, high-dimensional objects, such as text, video, or audio. This provides a challenge to traditional causal effect estimation. While leveraging the shared structure across different treatments can help generalize to unseen treatments at test time, we show in this paper that using such structure blindly can lead to biased causal effect estimation. We address this challenge by devising a novel contrastive approach to learn a representation of the high-dimensional treatments, and prove that it identifies underlying causal factors and discards non-causally relevant factors. We prove that this treatment representation leads to unbiased estimates of the causal effect, and empirically validate and benchmark our results on synthetic and real-world datasets.
Spillover Detection for Donor Selection in Synthetic Control Models
Jun 17, 2024Synthetic control (SC) models are widely used to estimate causal effects in settings with observational time-series data. To identify the causal effect on a target unit, SC requires the existence of correlated units that are not impacted by the intervention. Given one of these potential donor units, how can we decide whether it is in fact a valid donor - that is, one not subject to spillover effects from the intervention? Such a decision typically requires appealing to strong a priori domain knowledge specifying the units, which becomes infeasible in situations with large pools of potential donors. In this paper, we introduce a practical, theoretically-grounded donor selection procedure, aiming to weaken this domain knowledge requirement. Our main result is a Theorem that yields the assumptions required to identify donor values at post-intervention time points using only pre-intervention data. We show how this Theorem - and the assumptions underpinning it - can be turned into a practical method for detecting potential spillover effects and excluding invalid donors when constructing SCs. Importantly, we employ sensitivity analysis to formally bound the bias in our SC causal estimate in situations where an excluded donor was indeed valid, or where a selected donor was invalid. Using ideas from the proximal causal inference and instrumental variables literature, we show that the excluded donors can nevertheless be leveraged to further debias causal effect estimates. Finally, we illustrate our donor selection procedure on both simulated and real-world datasets.