 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaved2Paradise: Cost-Effective and Scalable LiDAR Simulation by Factoring the Real World
Dec 02, 2023To achieve strong real world performance, neural networks must be trained on large, diverse datasets; however, obtaining and annotating such datasets is costly and time-consuming, particularly for 3D point clouds. In this paper, we describe Paved2Paradise, a simple, cost-effective approach for generating fully labeled, diverse, and realistic lidar datasets from scratch, all while requiring minimal human annotation. Our key insight is that, by deliberately collecting separate "background" and "object" datasets (i.e., "factoring the real world"), we can intelligently combine them to produce a combinatorially large and diverse training set. The Paved2Paradise pipeline thus consists of four steps: (1) collecting copious background data, (2) recording individuals from the desired object class(es) performing different behaviors in an isolated environment (like a parking lot), (3) bootstrapping labels for the object dataset, and (4) generating samples by placing objects at arbitrary locations in backgrounds. To demonstrate the utility of Paved2Paradise, we generated synthetic datasets for two tasks: (1) human detection in orchards (a task for which no public data exists) and (2) pedestrian detection in urban environments. Qualitatively, we find that a model trained exclusively on Paved2Paradise synthetic data is highly effective at detecting humans in orchards, including when individuals are heavily occluded by tree branches. Quantitatively, a model trained on Paved2Paradise data that sources backgrounds from KITTI performs comparably to a model trained on the actual dataset. These results suggest the Paved2Paradise synthetic data pipeline can help accelerate point cloud model development in sectors where acquiring lidar datasets has previously been cost-prohibitive.
AQuaMaM: An Autoregressive, Quaternion Manifold Model for Rapidly Estimating Complex SO(3) Distributions
Jan 21, 2023Accurately modeling complex, multimodal distributions is necessary for optimal decision-making, but doing so for rotations in three-dimensions, i.e., the SO(3) group, is challenging due to the curvature of the rotation manifold. The recently described implicit-PDF (IPDF) is a simple, elegant, and effective approach for learning arbitrary distributions on SO(3) up to a given precision. However, inference with IPDF requires $N$ forward passes through the network's final multilayer perceptron (where $N$ places an upper bound on the likelihood that can be calculated by the model), which is prohibitively slow for those without the computational resources necessary to parallelize the queries. In this paper, I introduce AQuaMaM, a neural network capable of both learning complex distributions on the rotation manifold and calculating exact likelihoods for query rotations in a single forward pass. Specifically, AQuaMaM autoregressively models the projected components of unit quaternions as mixtures of uniform distributions that partition their geometrically-restricted domain of values. When trained on an "infinite" toy dataset with ambiguous viewpoints, AQuaMaM rapidly converges to a sampling distribution closely matching the true data distribution. In contrast, the sampling distribution for IPDF dramatically diverges from the true data distribution, despite IPDF approaching its theoretical minimum evaluation loss during training. When trained on a constructed dataset of 500,000 renders of a die in different rotations, AQuaMaM reaches a test log-likelihood 14% higher than IPDF. Further, compared to IPDF, AQuaMaM uses 24% fewer parameters, has a prediction throughput 52$\times$ faster on a single GPU, and converges in a similar amount of time during training.
The DEformer: An Order-Agnostic Distribution Estimating Transformer
Jul 11, 2021
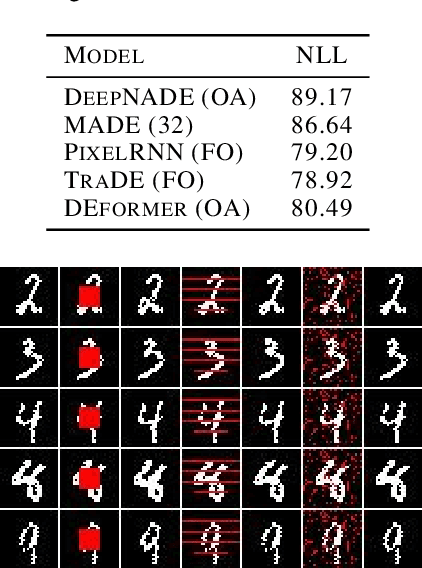
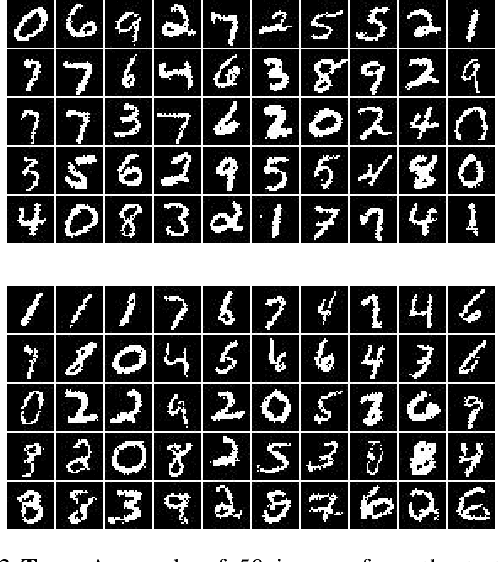

Order-agnostic autoregressive distribution (density) estimation (OADE), i.e., autoregressive distribution estimation where the features can occur in an arbitrary order, is a challenging problem in generative machine learning. Prior work on OADE has encoded feature identity by assigning each feature to a distinct fixed position in an input vector. As a result, architectures built for these inputs must strategically mask either the input or model weights to learn the various conditional distributions necessary for inferring the full joint distribution of the dataset in an order-agnostic way. In this paper, we propose an alternative approach for encoding feature identities, where each feature's identity is included alongside its value in the input. This feature identity encoding strategy allows neural architectures designed for sequential data to be applied to the OADE task without modification. As a proof of concept, we show that a Transformer trained on this input (which we refer to as "the DEformer", i.e., the distribution estimating Transformer) can effectively model binarized-MNIST, approaching the performance of fixed-order autoregressive distribution estimating algorithms while still being entirely order-agnostic. Additionally, we find that the DEformer surpasses the performance of recent flow-based architectures when modeling a tabular dataset.
baller2vec++: A Look-Ahead Multi-Entity Transformer For Modeling Coordinated Agents
Apr 24, 2021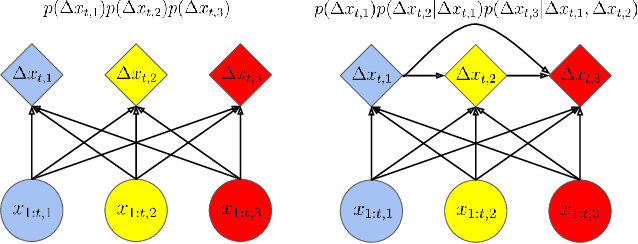
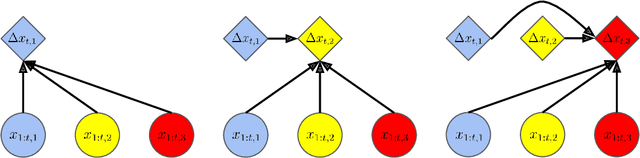
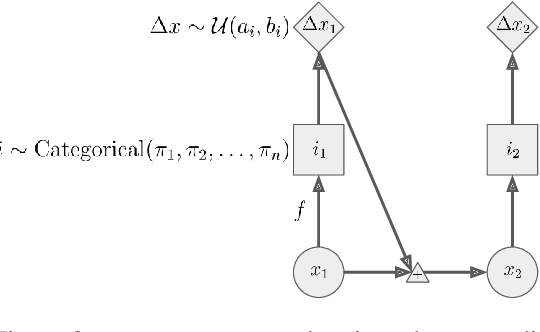

In many multi-agent spatiotemporal systems, the agents are under the influence of shared, unobserved variables (e.g., the play a team is executing in a game of basketball). As a result, the trajectories of the agents are often statistically dependent at any given time step; however, almost universally, multi-agent models implicitly assume the agents' trajectories are statistically independent at each time step. In this paper, we introduce baller2vec++, a multi-entity Transformer that can effectively model coordinated agents. Specifically, baller2vec++ applies a specially designed self-attention mask to a mixture of location and "look-ahead" trajectory sequences to learn the distributions of statistically dependent agent trajectories. We show that, unlike baller2vec (baller2vec++'s predecessor), baller2vec++ can learn to emulate the behavior of perfectly coordinated agents in a simulated toy dataset. Additionally, when modeling the trajectories of professional basketball players, baller2vec++ outperforms baller2vec by a wide margin.
baller2vec: A Multi-Entity Transformer For Multi-Agent Spatiotemporal Modeling
Feb 05, 2021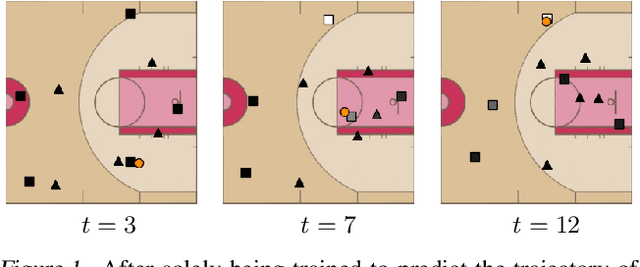

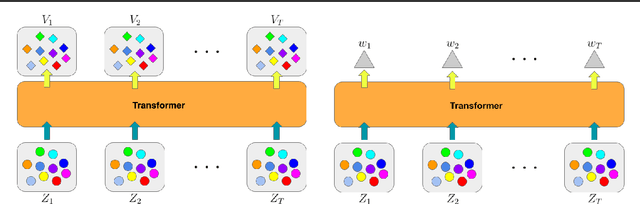
Multi-agent spatiotemporal modeling is a challenging task from both an algorithmic design and computational complexity perspective. Recent work has explored the efficacy of traditional deep sequential models in this domain, but these architectures are slow and cumbersome to train, particularly as model size increases. Further, prior attempts to model interactions between agents across time have limitations, such as imposing an order on the agents, or making assumptions about their relationships. In this paper, we introduce baller2vec, a multi-entity generalization of the standard Transformer that, with minimal assumptions, can simultaneously and efficiently integrate information across entities and time. We test the effectiveness of baller2vec for multi-agent spatiotemporal modeling by training it to perform two different basketball-related tasks: (1) simultaneously forecasting the trajectories of all players on the court and (2) forecasting the trajectory of the ball. Not only does baller2vec learn to perform these tasks well, it also appears to "understand" the game of basketball, encoding idiosyncratic qualities of players in its embeddings, and performing basketball-relevant functions with its attention heads.
Strike a Pose: Neural Networks Are Easily Fooled by Strange Poses of Familiar Objects
Nov 28, 2018
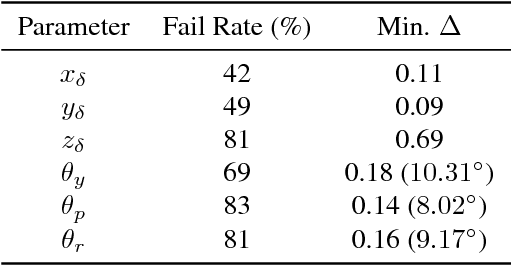
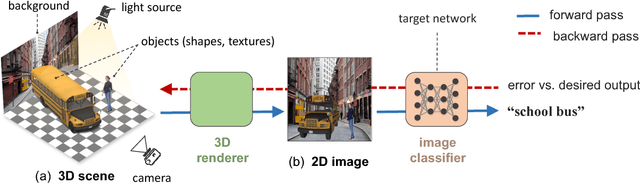

Despite excellent performance on stationary test sets, deep neural networks (DNNs) can fail to generalize to out-of-distribution (OoD) inputs, including natural, non-adversarial ones, which are common in real-world settings. In this paper, we present a framework for discovering DNN failures that harnesses 3D renderers and 3D models. That is, we estimate the parameters of a 3D renderer that cause a target DNN to misbehave in response to the rendered image. Using our framework and a self-assembled dataset of 3D objects, we investigate the vulnerability of DNNs to OoD poses of well-known objects in ImageNet. For objects that are readily recognized by DNNs in their canonical poses, DNNs incorrectly classify 97% of their pose space. In addition, DNNs are highly sensitive to slight pose perturbations. Importantly, adversarial poses transfer across models and datasets. We find that 99.9% and 99.4% of the poses misclassified by Inception-v3 also transfer to the AlexNet and ResNet-50 image classifiers trained on the same ImageNet dataset, respectively, and 75.5% transfer to the YOLOv3 object detector trained on MS COCO.