 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNecessity of Cooperative Transmissions for Wireless MapReduce
Jan 17, 2026The paper presents an improved upper bound (achievability result) on the optimal tradeoff between Normalized Delivery Time (NDT) and computation load for distributed computing MapReduce systems in certain ranges of the parameters. The upper bound is based on interference alignment combined with zero-forcing. The paper further provides a lower bound (converse) on the optimal NDT-computation tradeoff that can be achieved when IVAs are partitioned into sub-IVAs, and these sub-IVAs are then transmitted (in an arbitrary form) by a single node, without cooperation among nodes. For appropriate linear functions (e.g., XORs), such non-cooperative schemes can achieve some of the best NDT-computation tradeoff points so far obtained in the literature. However, as our lower bound shows, any non-cooperative scheme achieves a worse NDT-computation tradeoff than our new proposed scheme for certain parameters, thus proving the necessity of cooperative schemes like zero-forcing to attain the optimal NDT-computation tradeoff.
Distributed Hypothesis Testing Under A Covertness Constraint
Jan 14, 2026We study distributed hypothesis testing under a covertness constraint in the non-alert situation, which requires that under the null-hypothesis an external warden be unable to detect whether communication between the sensor and the decision center is taking place. We characterize the achievable Stein exponent of this setup when the channel from the sensor to the decision center is a partially-connected discrete memoryless channel (DMC), i.e., when certain output symbols can only be induced by some of the inputs. The Stein-exponent in this case, does not depend on the specific transition law of the DMC and equals Shalaby and Papamarcou's exponent without a warden but where the sensor can send $k$ noise-free bits to the decision center, for $k$ a function that is sublinear in the observation length $n$. For fully-connected DMCs, we propose an achievable Stein-exponent and show that it can improve over the local exponent at the decision center. All our coding schemes do not require that the sensor and decision center share a common secret key, as commonly assumed in covert communication. Moreover, in our schemes the divergence covertness constraint vanishes (almost) exponentially fast in the obervation length $n$, again, an atypical behaviour for covert communication.
A Memory-Based Reinforcement Learning Approach to Integrated Sensing and Communication
Dec 02, 2024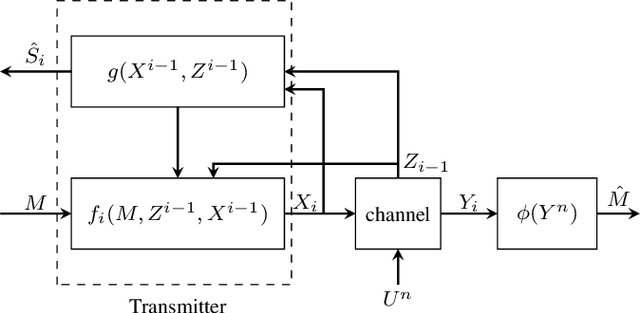


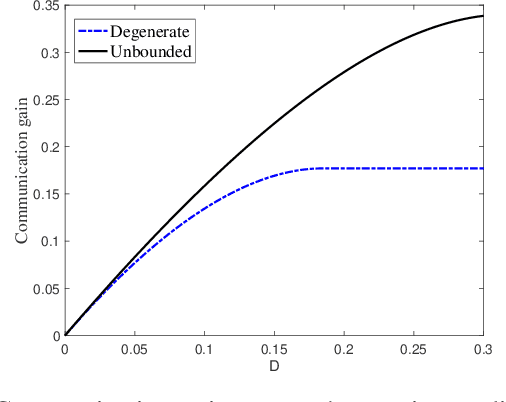
In this paper, we consider a point-to-point integrated sensing and communication (ISAC) system, where a transmitter conveys a message to a receiver over a channel with memory and simultaneously estimates the state of the channel through the backscattered signals from the emitted waveform. Using Massey's concept of directed information for channels with memory, we formulate the capacity-distortion tradeoff for the ISAC problem when sensing is performed in an online fashion. Optimizing the transmit waveform for this system to simultaneously achieve good communication and sensing performance is a complicated task, and thus we propose a deep reinforcement learning (RL) approach to find a solution. The proposed approach enables the agent to optimize the ISAC performance by learning a reward that reflects the difference between the communication gain and the sensing loss. Since the state-space in our RL model is \`a priori unbounded, we employ deep deterministic policy gradient algorithm (DDPG). Our numerical results suggest a significant performance improvement when one considers unbounded state-space as opposed to a simpler RL problem with reduced state-space. In the extreme case of degenerate state-space only memoryless signaling strategies are possible. Our results thus emphasize the necessity of well exploiting the memory inherent in ISAC systems.