 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Memory-Based Reinforcement Learning Approach to Integrated Sensing and Communication
Paper and Code
Dec 02, 2024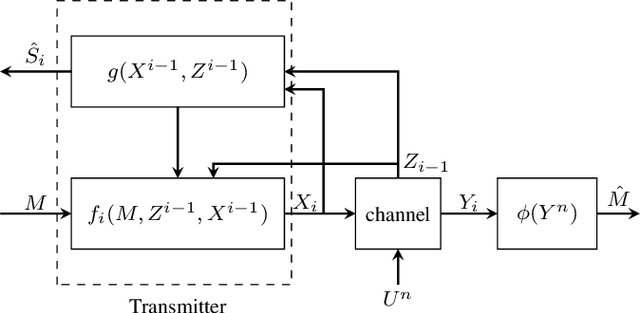


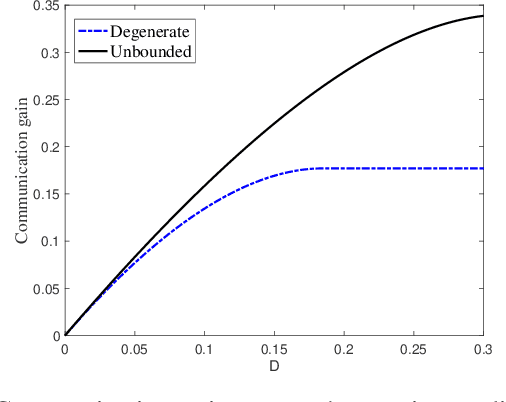
In this paper, we consider a point-to-point integrated sensing and communication (ISAC) system, where a transmitter conveys a message to a receiver over a channel with memory and simultaneously estimates the state of the channel through the backscattered signals from the emitted waveform. Using Massey's concept of directed information for channels with memory, we formulate the capacity-distortion tradeoff for the ISAC problem when sensing is performed in an online fashion. Optimizing the transmit waveform for this system to simultaneously achieve good communication and sensing performance is a complicated task, and thus we propose a deep reinforcement learning (RL) approach to find a solution. The proposed approach enables the agent to optimize the ISAC performance by learning a reward that reflects the difference between the communication gain and the sensing loss. Since the state-space in our RL model is \`a priori unbounded, we employ deep deterministic policy gradient algorithm (DDPG). Our numerical results suggest a significant performance improvement when one considers unbounded state-space as opposed to a simpler RL problem with reduced state-space. In the extreme case of degenerate state-space only memoryless signaling strategies are possible. Our results thus emphasize the necessity of well exploiting the memory inherent in ISAC systems.