 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Enhancing Machine Learning via Removal of Unwanted Dependencies
Aug 04, 2020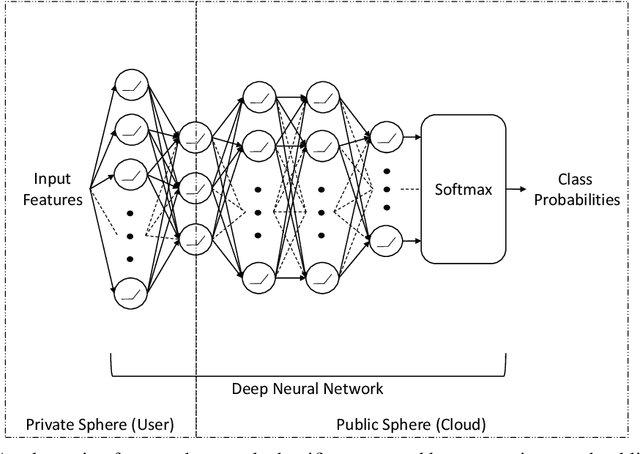

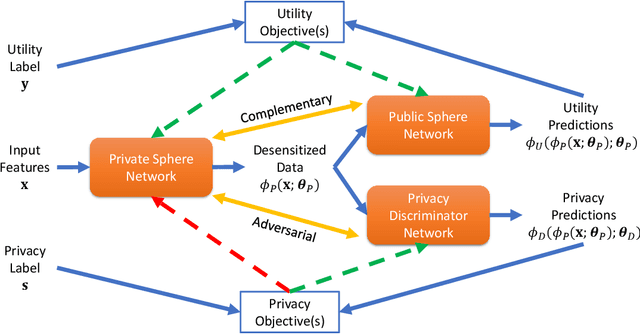
The rapid rise of IoT and Big Data has facilitated copious data driven applications to enhance our quality of life. However, the omnipresent and all-encompassing nature of the data collection can generate privacy concerns. Hence, there is a strong need to develop techniques that ensure the data serve only the intended purposes, giving users control over the information they share. To this end, this paper studies new variants of supervised and adversarial learning methods, which remove the sensitive information in the data before they are sent out for a particular application. The explored methods optimize privacy preserving feature mappings and predictive models simultaneously in an end-to-end fashion. Additionally, the models are built with an emphasis on placing little computational burden on the user side so that the data can be desensitized on device in a cheap manner. Experimental results on mobile sensing and face datasets demonstrate that our models can successfully maintain the utility performances of predictive models while causing sensitive predictions to perform poorly.
Scalable Kernel Learning via the Discriminant Information
Sep 23, 2019
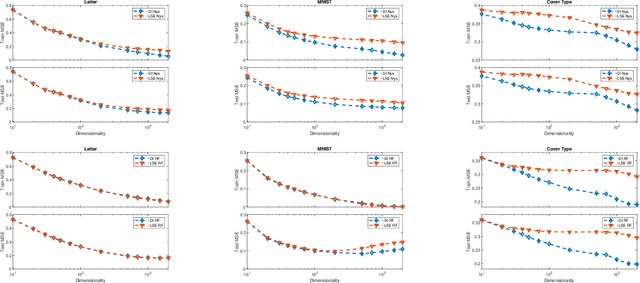
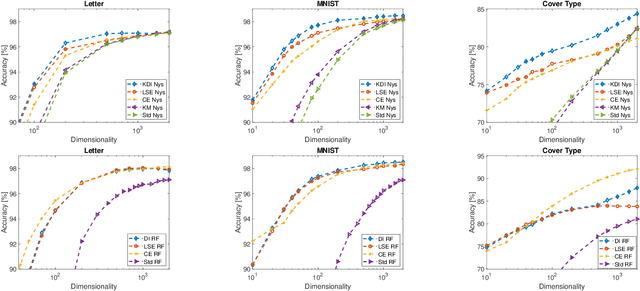
Kernel approximation methods have been popular techniques for scalable kernel based learning. They create explicit, low-dimensional kernel feature maps to deal with the high computational and memory complexity of standard techniques. This work studies a supervised kernel learning methodology to optimize such mappings. We utilize the Discriminant Information criterion, a measure of class separability, which is extended to cover a wider range of kernels. By exploiting the connection of this criterion to the minimum Kernel Ridge Regression loss, we propose a novel training strategy that is especially suitable for stochastic gradient methods, allowing kernel optimization to scale to large datasets. Experimental results on 3 datasets showcase that our techniques can improve optimization and generalization performances over state of the art kernel learning methods.
Supervising Nyström Methods via Negative Margin Support Vector Selection
May 18, 2018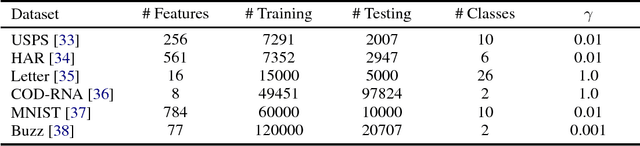
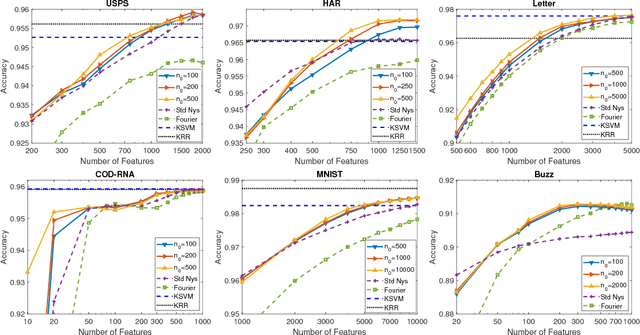
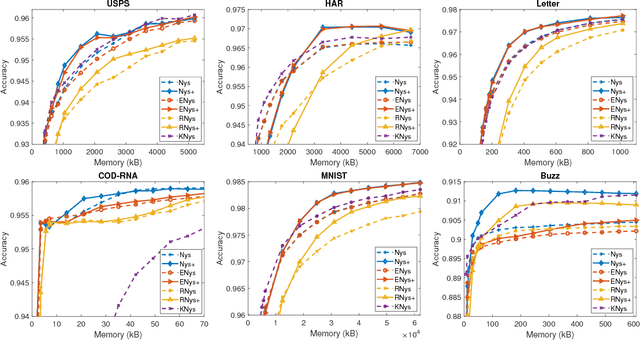
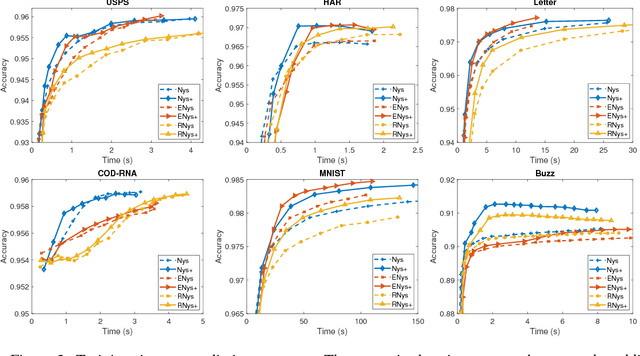
The Nystr\"om methods have been popular techniques for scalable kernel based learning. They approximate explicit, low-dimensional feature mappings for kernel functions from the pairwise comparisons with the training data. However, Nystr\"om methods are generally applied without the supervision provided by the training labels in the classification/regression problems. This leads to pairwise comparisons with randomly chosen training samples in the model. Conversely, this work studies a supervised Nystr\"om method that chooses the critical subsets of samples for the success of the Machine Learning model. Particularly, we select the Nystr\"om support vectors via the negative margin criterion, and create explicit feature maps that are more suitable for the classification task on the data. Experimental results on six datasets show that, without increasing the complexity over unsupervised techniques, our method can significantly improve the classification performance achieved via kernel approximation methods and reduce the number of features needed to reach or exceed the performance of the full-dimensional kernel machines.
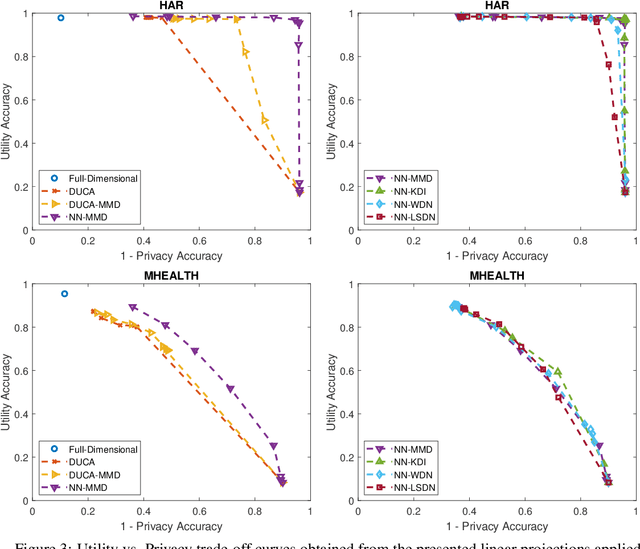
Ratio Utility and Cost Analysis for Privacy Preserving Subspace Projection
Feb 26, 2017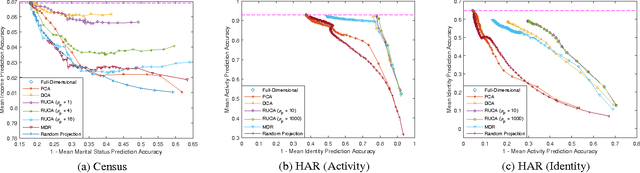
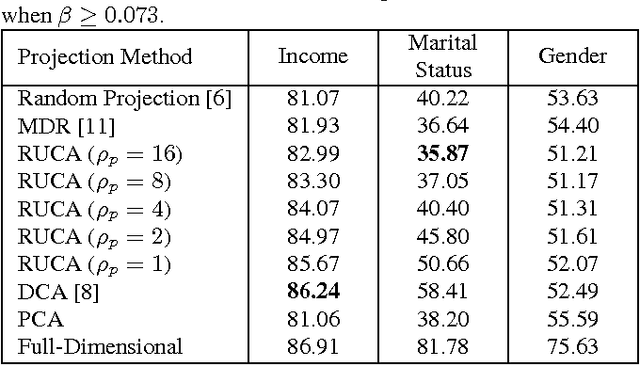
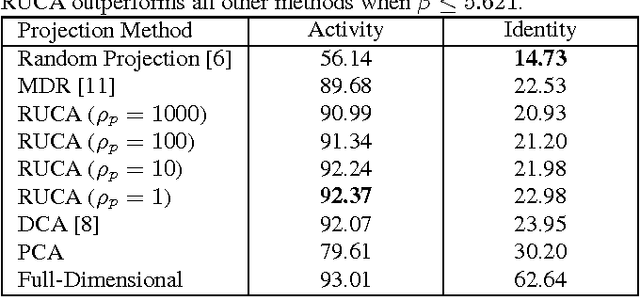
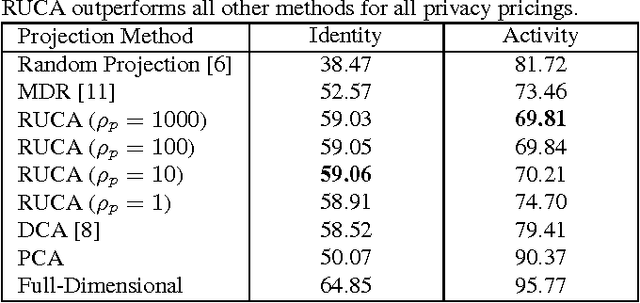
With a rapidly increasing number of devices connected to the internet, big data has been applied to various domains of human life. Nevertheless, it has also opened new venues for breaching users' privacy. Hence it is highly required to develop techniques that enable data owners to privatize their data while keeping it useful for intended applications. Existing methods, however, do not offer enough flexibility for controlling the utility-privacy trade-off and may incur unfavorable results when privacy requirements are high. To tackle these drawbacks, we propose a compressive-privacy based method, namely RUCA (Ratio Utility and Cost Analysis), which can not only maximize performance for a privacy-insensitive classification task but also minimize the ability of any classifier to infer private information from the data. Experimental results on Census and Human Activity Recognition data sets demonstrate that RUCA significantly outperforms existing privacy preserving data projection techniques for a wide range of privacy pricings.