 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervising Nyström Methods via Negative Margin Support Vector Selection
Paper and Code
May 18, 2018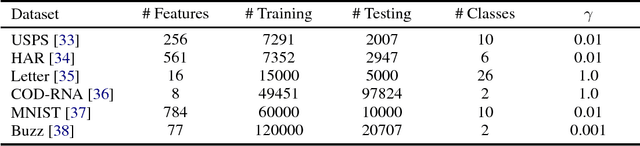
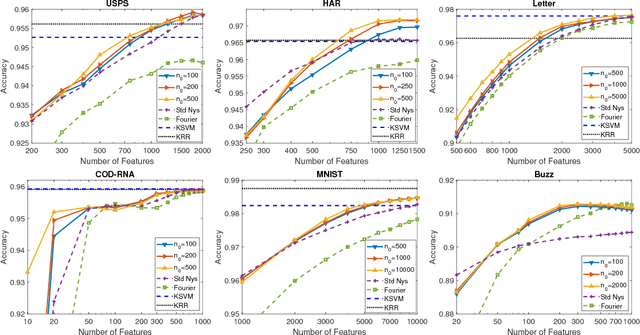
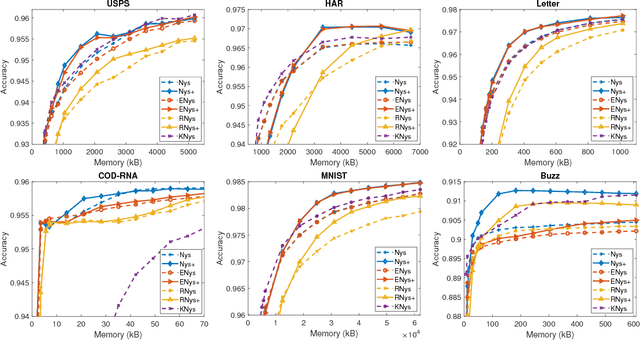
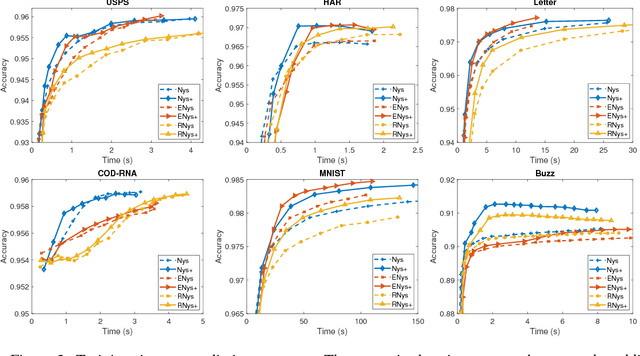
The Nystr\"om methods have been popular techniques for scalable kernel based learning. They approximate explicit, low-dimensional feature mappings for kernel functions from the pairwise comparisons with the training data. However, Nystr\"om methods are generally applied without the supervision provided by the training labels in the classification/regression problems. This leads to pairwise comparisons with randomly chosen training samples in the model. Conversely, this work studies a supervised Nystr\"om method that chooses the critical subsets of samples for the success of the Machine Learning model. Particularly, we select the Nystr\"om support vectors via the negative margin criterion, and create explicit feature maps that are more suitable for the classification task on the data. Experimental results on six datasets show that, without increasing the complexity over unsupervised techniques, our method can significantly improve the classification performance achieved via kernel approximation methods and reduce the number of features needed to reach or exceed the performance of the full-dimensional kernel machines.