 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Enhancing Machine Learning via Removal of Unwanted Dependencies
Aug 04, 2020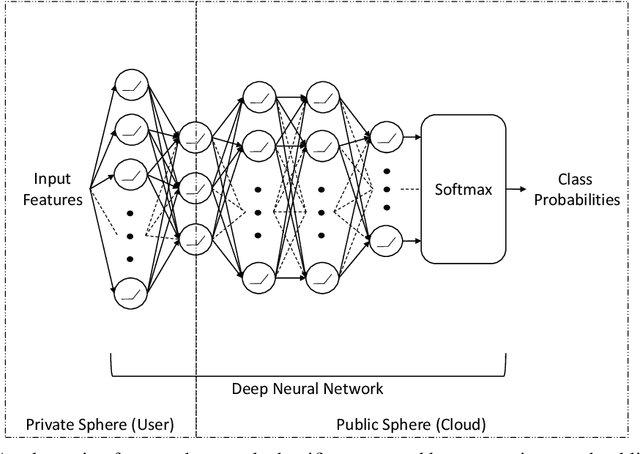

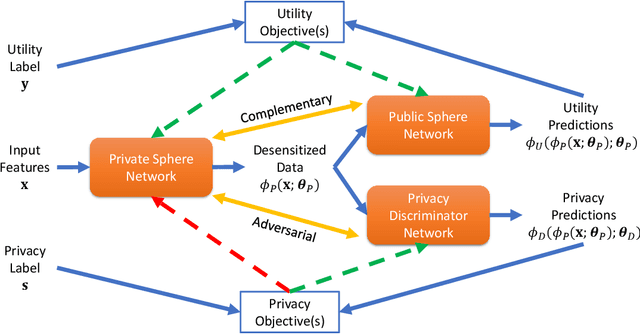
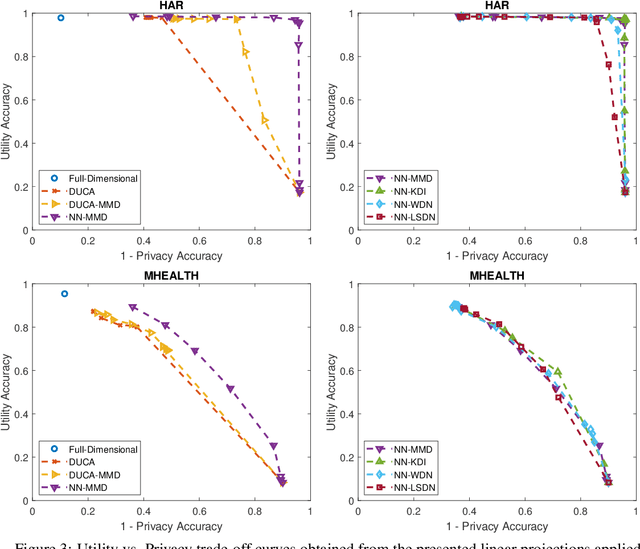
The rapid rise of IoT and Big Data has facilitated copious data driven applications to enhance our quality of life. However, the omnipresent and all-encompassing nature of the data collection can generate privacy concerns. Hence, there is a strong need to develop techniques that ensure the data serve only the intended purposes, giving users control over the information they share. To this end, this paper studies new variants of supervised and adversarial learning methods, which remove the sensitive information in the data before they are sent out for a particular application. The explored methods optimize privacy preserving feature mappings and predictive models simultaneously in an end-to-end fashion. Additionally, the models are built with an emphasis on placing little computational burden on the user side so that the data can be desensitized on device in a cheap manner. Experimental results on mobile sensing and face datasets demonstrate that our models can successfully maintain the utility performances of predictive models while causing sensitive predictions to perform poorly.
Information-Theoretic Bounds on the Generalization Error and Privacy Leakage in Federated Learning
May 05, 2020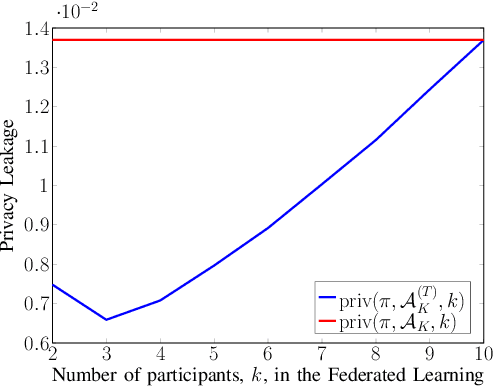
Machine learning algorithms operating on mobile networks can be characterized into three different categories. First is the classical situation in which the end-user devices send their data to a central server where this data is used to train a model. Second is the distributed setting in which each device trains its own model and send its model parameters to a central server where these model parameters are aggregated to create one final model. Third is the federated learning setting in which, at any given time $t$, a certain number of active end users train with their own local data along with feedback provided by the central server and then send their newly estimated model parameters to the central server. The server, then, aggregates these new parameters, updates its own model, and feeds the updated parameters back to all the end users, continuing this process until it converges. The main objective of this work is to provide an information-theoretic framework for all of the aforementioned learning paradigms. Moreover, using the provided framework, we develop upper and lower bounds on the generalization error together with bounds on the privacy leakage in the classical, distributed and federated learning settings. Keywords: Federated Learning, Distributed Learning, Machine Learning, Model Aggregation.