 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Deep Learning-based Proximal Gradient Descent for MR Reconstruction
Nov 30, 2022The data consistency for the physical forward model is crucial in inverse problems, especially in MR imaging reconstruction. The standard way is to unroll an iterative algorithm into a neural network with a forward model embedded. The forward model always changes in clinical practice, so the learning component's entanglement with the forward model makes the reconstruction hard to generalize. The proposed method is more generalizable for different MR acquisition settings by separating the forward model from the deep learning component. The deep learning-based proximal gradient descent was proposed to create a learned regularization term independent of the forward model. We applied the one-time trained regularization term to different MR acquisition settings to validate the proposed method and compared the reconstruction with the commonly used $\ell_1$ regularization. We showed ~3 dB improvement in the peak signal to noise ratio, compared with conventional $\ell_1$ regularized reconstruction. We demonstrated the flexibility of the proposed method in choosing different undersampling patterns. We also evaluated the effect of parameter tuning for the deep learning regularization.
Three-Dimensional Embedded Attentive RNN (3D-EAR) Segmentor for Left Ventricle Delineation from Myocardial Velocity Mapping
Apr 26, 2021
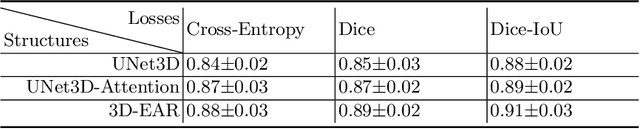
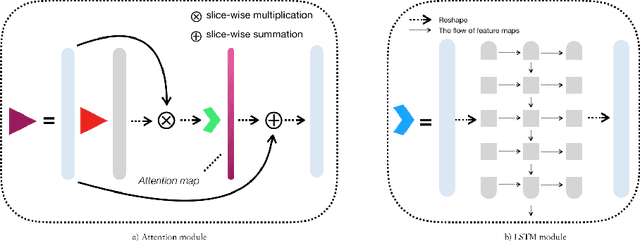

Myocardial Velocity Mapping Cardiac MR (MVM-CMR) can be used to measure global and regional myocardial velocities with proved reproducibility. Accurate left ventricle delineation is a prerequisite for robust and reproducible myocardial velocity estimation. Conventional manual segmentation on this dataset can be time-consuming and subjective, and an effective fully automated delineation method is highly in demand. By leveraging recently proposed deep learning-based semantic segmentation approaches, in this study, we propose a novel fully automated framework incorporating a 3D-UNet backbone architecture with Embedded multichannel Attention mechanism and LSTM based Recurrent neural networks (RNN) for the MVM-CMR datasets (dubbed 3D-EAR segmentor). The proposed method also utilises the amalgamation of magnitude and phase images as input to realise an information fusion of this multichannel dataset and exploring the correlations of temporal frames via the embedded RNN. By comparing the baseline model of 3D-UNet and ablation studies with and without embedded attentive LSTM modules and various loss functions, we can demonstrate that the proposed model has outperformed the state-of-the-art baseline models with significant improvement.