 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Neural Network For Personalized Federated Learning Parameter Selection
Feb 25, 2024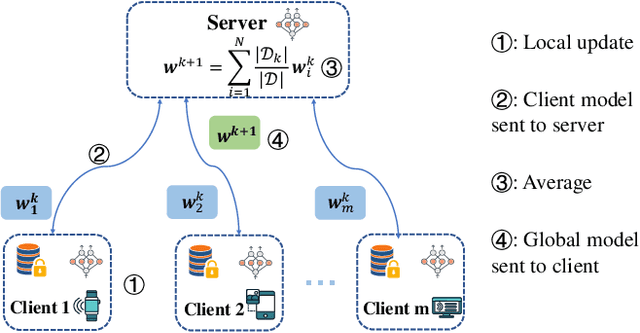
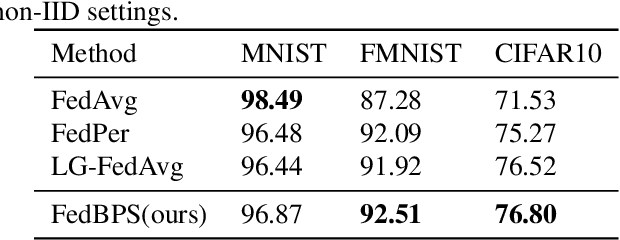
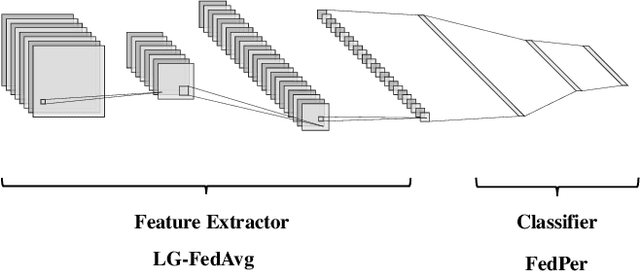
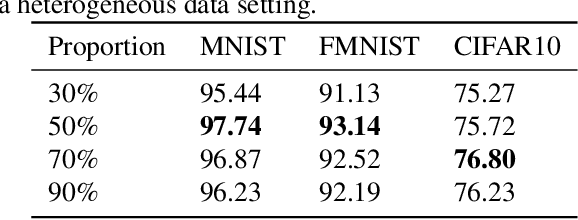
Federated learning's poor performance in the presence of heterogeneous data remains one of the most pressing issues in the field. Personalized federated learning departs from the conventional paradigm in which all clients employ the same model, instead striving to discover an individualized model for each client to address the heterogeneity in the data. One of such approach involves personalizing specific layers of neural networks. However, prior endeavors have not provided a dependable rationale, and some have selected personalized layers that are entirely distinct and conflicting. In this work, we take a step further by proposing personalization at the elemental level, rather than the traditional layer-level personalization. To select personalized parameters, we introduce Bayesian neural networks and rely on the uncertainty they offer to guide our selection of personalized parameters. Finally, we validate our algorithm's efficacy on several real-world datasets, demonstrating that our proposed approach outperforms existing baselines.
Trustworthy Personalized Bayesian Federated Learning via Posterior Fine-Tune
Feb 25, 2024



Performance degradation owing to data heterogeneity and low output interpretability are the most significant challenges faced by federated learning in practical applications. Personalized federated learning diverges from traditional approaches, as it no longer seeks to train a single model, but instead tailors a unique personalized model for each client. However, previous work focused only on personalization from the perspective of neural network parameters and lack of robustness and interpretability. In this work, we establish a novel framework for personalized federated learning, incorporating Bayesian methodology which enhances the algorithm's ability to quantify uncertainty. Furthermore, we introduce normalizing flow to achieve personalization from the parameter posterior perspective and theoretically analyze the impact of normalizing flow on out-of-distribution (OOD) detection for Bayesian neural networks. Finally, we evaluated our approach on heterogeneous datasets, and the experimental results indicate that the new algorithm not only improves accuracy but also outperforms the baseline significantly in OOD detection due to the reliable output of the Bayesian approach.
Deep Leakage from Model in Federated Learning
Jun 10, 2022
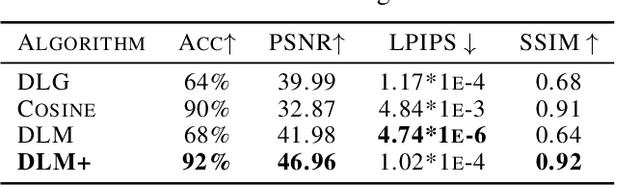

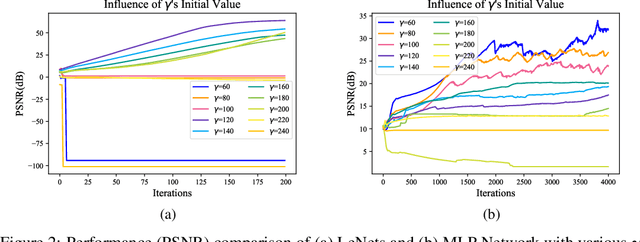
Distributed machine learning has been widely used in recent years to tackle the large and complex dataset problem. Therewith, the security of distributed learning has also drawn increasing attentions from both academia and industry. In this context, federated learning (FL) was developed as a "secure" distributed learning by maintaining private training data locally and only public model gradients are communicated between. However, to date, a variety of gradient leakage attacks have been proposed for this procedure and prove that it is insecure. For instance, a common drawback of these attacks is shared: they require too much auxiliary information such as model weights, optimizers, and some hyperparameters (e.g., learning rate), which are difficult to obtain in real situations. Moreover, many existing algorithms avoid transmitting model gradients in FL and turn to sending model weights, such as FedAvg, but few people consider its security breach. In this paper, we present two novel frameworks to demonstrate that transmitting model weights is also likely to leak private local data of clients, i.e., (DLM and DLM+), under the FL scenario. In addition, a number of experiments are performed to illustrate the effect and generality of our attack frameworks. At the end of this paper, we also introduce two defenses to the proposed attacks and evaluate their protection effects. Comprehensively, the proposed attack and defense schemes can be applied to the general distributed learning scenario as well, just with some appropriate customization.