 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation of Cellular Patterns in Confocal Images of Melanocytic Lesions in vivo via a Multiscale Encoder-Decoder Network (MED-Net)
Jan 03, 2020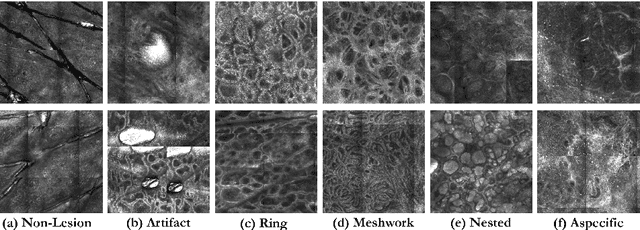
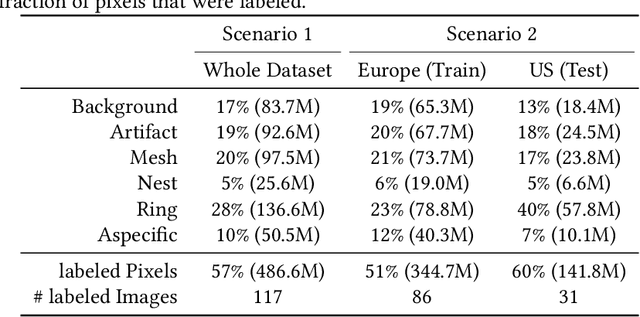
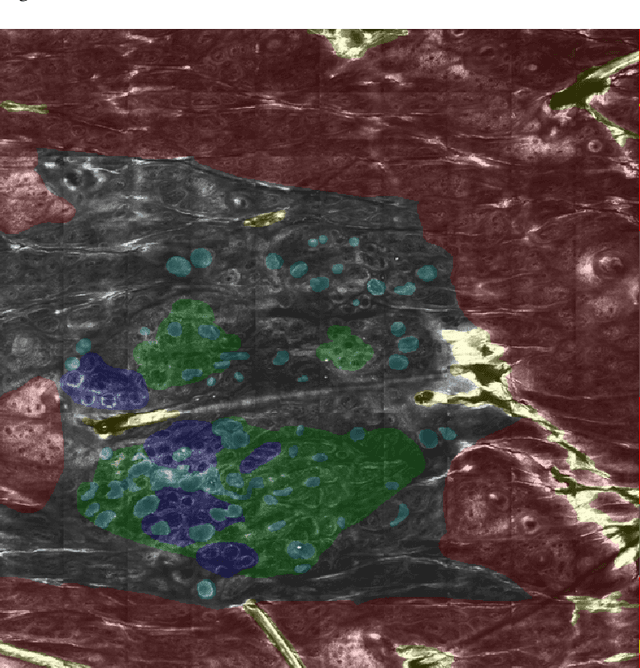
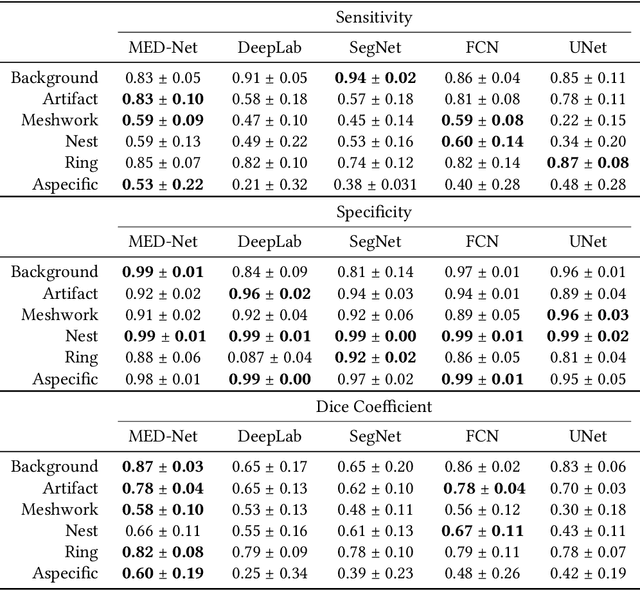
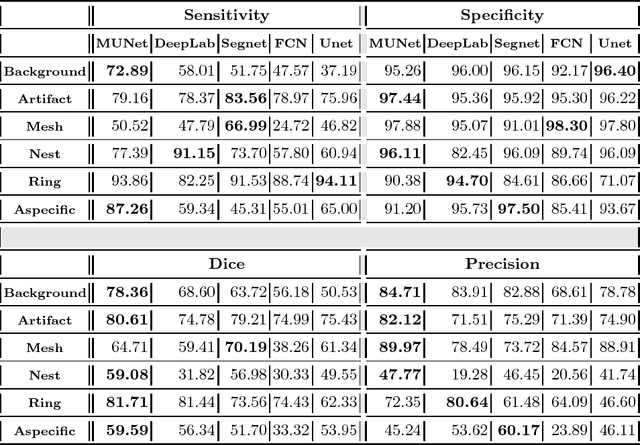
In-vivo optical microscopy is advancing into routine clinical practice for non-invasively guiding diagnosis and treatment of cancer and other diseases, and thus beginning to reduce the need for traditional biopsy. However, reading and analysis of the optical microscopic images are generally still qualitative, relying mainly on visual examination. Here we present an automated semantic segmentation method called "Multiscale Encoder-Decoder Network (MED-Net)" that provides pixel-wise labeling into classes of patterns in a quantitative manner. The novelty in our approach is the modeling of textural patterns at multiple scales. This mimics the procedure for examining pathology images, which routinely starts with low magnification (low resolution, large field of view) followed by closer inspection of suspicious areas with higher magnification (higher resolution, smaller fields of view). We trained and tested our model on non-overlapping partitions of 117 reflectance confocal microscopy (RCM) mosaics of melanocytic lesions, an extensive dataset for this application, collected at four clinics in the US, and two in Italy. With patient-wise cross-validation, we achieved pixel-wise mean sensitivity and specificity of $70\pm11\%$ and $95\pm2\%$, respectively, with $0.71\pm0.09$ Dice coefficient over six classes. In the scenario, we partitioned the data clinic-wise and tested the generalizability of the model over multiple clinics. In this setting, we achieved pixel-wise mean sensitivity and specificity of $74\%$ and $95\%$, respectively, with $0.75$ Dice coefficient. We compared MED-Net against the state-of-the-art semantic segmentation models and achieved better quantitative segmentation performance. Our results also suggest that, due to its nested multiscale architecture, the MED-Net model annotated RCM mosaics more coherently, avoiding unrealistic-fragmented annotations.
A Multiresolution Convolutional Neural Network with Partial Label Training for Annotating Reflectance Confocal Microscopy Images of Skin
Aug 23, 2018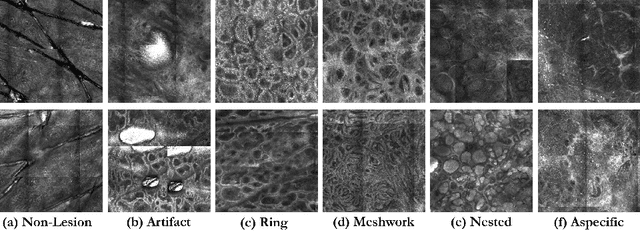
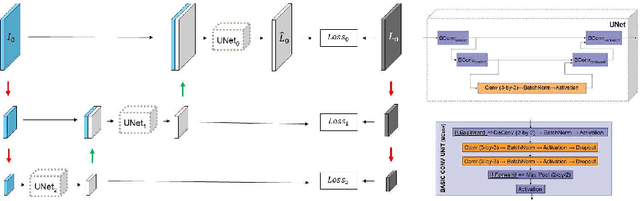

We describe a new multiresolution "nested encoder-decoder" convolutional network architecture and use it to annotate morphological patterns in reflectance confocal microscopy (RCM) images of human skin for aiding cancer diagnosis. Skin cancers are the most common types of cancers, melanoma being the deadliest among them. RCM is an effective, non-invasive pre-screening tool for skin cancer diagnosis, with the required cellular resolution. However, images are complex, low-contrast, and highly variable, so that clinicians require months to years of expert-level training to be able to make accurate assessments. In this paper, we address classifying 4 key clinically important structural/textural patterns in RCM images. The occurrence and morphology of these patterns are used by clinicians for diagnosis of melanomas. The large size of RCM images, the large variance of pattern size, the large-scale range over which patterns appear, the class imbalance in collected images, and the lack of fully-labeled images all make this a challenging problem to address, even with automated machine learning tools. We designed a novel nested U-net architecture to cope with these challenges, and a selective loss function to handle partial labeling. Trained and tested on 56 melanoma-suspicious, partially labeled, 12k x 12k pixel images, our network automatically annotated diagnostic patterns with high sensitivity and specificity, providing consistent labels for unlabeled sections of the test images. Providing such annotation will aid clinicians in achieving diagnostic accuracy, and perhaps more important, dramatically facilitate clinical training, thus enabling much more rapid adoption of RCM into widespread clinical use process. In addition, our adaptation of U-net architecture provides an intrinsically multiresolution deep network that may be useful in other challenging biomedical image analysis applications.