 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Motion Information from Unlabeled Videos for Static Image Action Recognition
Dec 01, 2019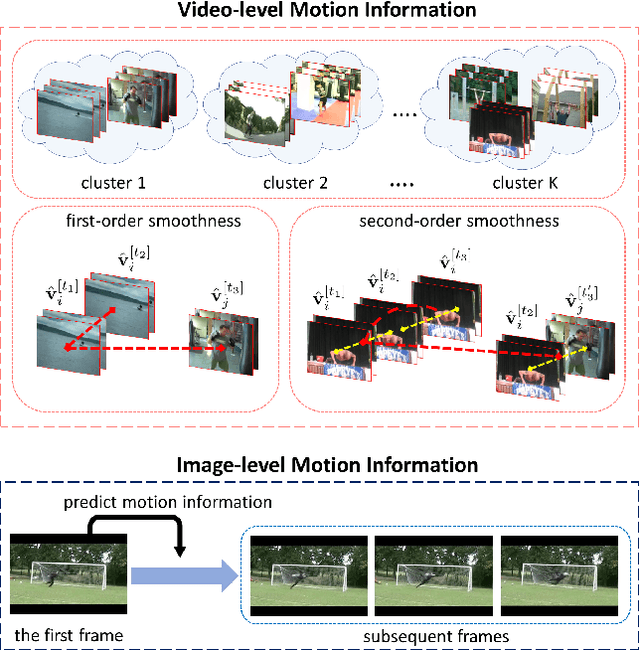
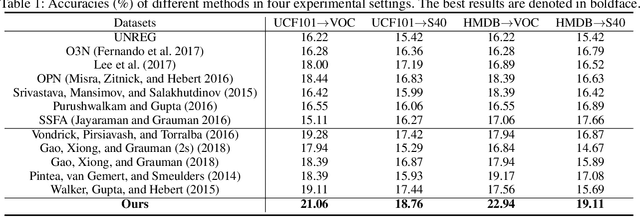
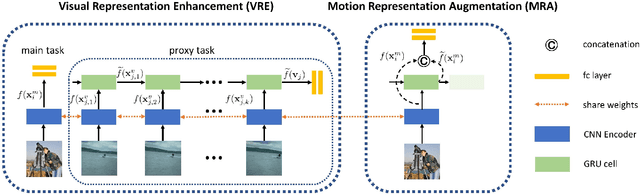
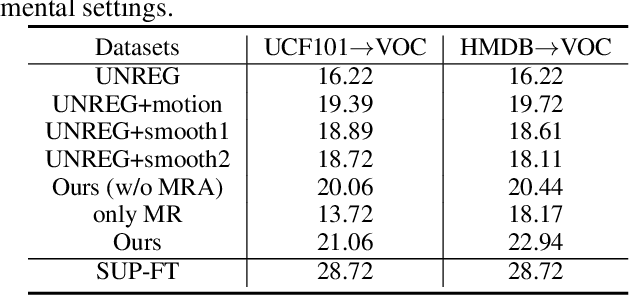
Static image action recognition, which aims to recognize action based on a single image, usually relies on expensive human labeling effort such as adequate labeled action images and large-scale labeled image dataset. In contrast, abundant unlabeled videos can be economically obtained. Therefore, several works have explored using unlabeled videos to facilitate image action recognition, which can be categorized into the following two groups: (a) enhance visual representations of action images with a designed proxy task on unlabeled videos, which falls into the scope of self-supervised learning; (b) generate auxiliary representations for action images with the generator learned from unlabeled videos. In this paper, we integrate the above two strategies in a unified framework, which consists of Visual Representation Enhancement (VRE) module and Motion Representation Augmentation (MRA) module. Specifically, the VRE module includes a proxy task which imposes pseudo motion label constraint and temporal coherence constraint on unlabeled videos, while the MRA module could predict the motion information of a static action image by exploiting unlabeled videos. We demonstrate the superiority of our framework based on four benchmark human action datasets with limited labeled data.