 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning over Wireless Networks: A Band-limited Coordinated Descent Approach
Feb 16, 2021

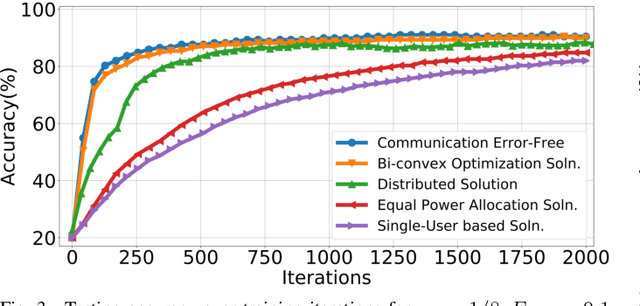

We consider a many-to-one wireless architecture for federated learning at the network edge, where multiple edge devices collaboratively train a model using local data. The unreliable nature of wireless connectivity, together with constraints in computing resources at edge devices, dictates that the local updates at edge devices should be carefully crafted and compressed to match the wireless communication resources available and should work in concert with the receiver. Thus motivated, we propose SGD-based bandlimited coordinate descent algorithms for such settings. Specifically, for the wireless edge employing over-the-air computing, a common subset of k-coordinates of the gradient updates across edge devices are selected by the receiver in each iteration, and then transmitted simultaneously over k sub-carriers, each experiencing time-varying channel conditions. We characterize the impact of communication error and compression, in terms of the resulting gradient bias and mean squared error, on the convergence of the proposed algorithms. We then study learning-driven communication error minimization via joint optimization of power allocation and learning rates. Our findings reveal that optimal power allocation across different sub-carriers should take into account both the gradient values and channel conditions, thus generalizing the widely used water-filling policy. We also develop sub-optimal distributed solutions amenable to implementation.
Continual Learning of Generative Models with Limited Data: From Wasserstein-1 Barycenter to Adaptive Coalescence
Jan 22, 2021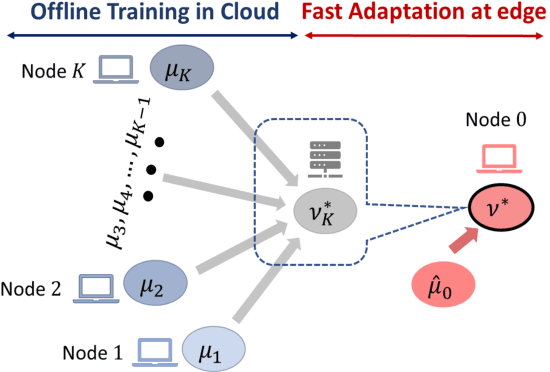

Learning generative models is challenging for a network edge node with limited data and computing power. Since tasks in similar environments share model similarity, it is plausible to leverage pre-trained generative models from the cloud or other edge nodes. Appealing to optimal transport theory tailored towards Wasserstein-1 generative adversarial networks (WGAN), this study aims to develop a framework which systematically optimizes continual learning of generative models using local data at the edge node while exploiting adaptive coalescence of pre-trained generative models. Specifically, by treating the knowledge transfer from other nodes as Wasserstein balls centered around their pre-trained models, continual learning of generative models is cast as a constrained optimization problem, which is further reduced to a Wasserstein-1 barycenter problem. A two-stage approach is devised accordingly: 1) The barycenters among the pre-trained models are computed offline, where displacement interpolation is used as the theoretic foundation for finding adaptive barycenters via a "recursive" WGAN configuration; 2) the barycenter computed offline is used as meta-model initialization for continual learning and then fast adaptation is carried out to find the generative model using the local samples at the target edge node. Finally, a weight ternarization method, based on joint optimization of weights and threshold for quantization, is developed to compress the generative model further.
Accelerating Distributed Online Meta-Learning via Multi-Agent Collaboration under Limited Communication
Dec 19, 2020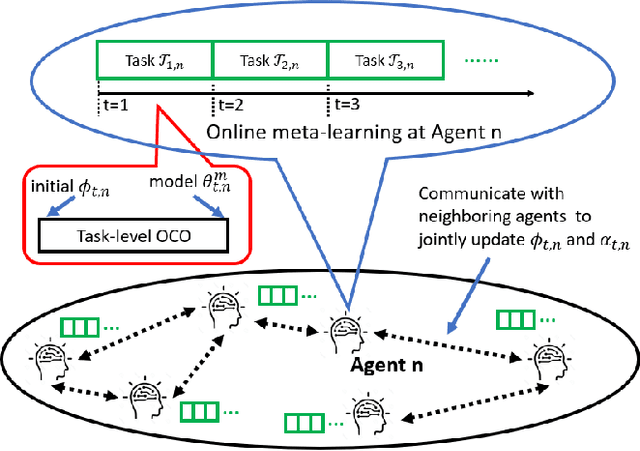


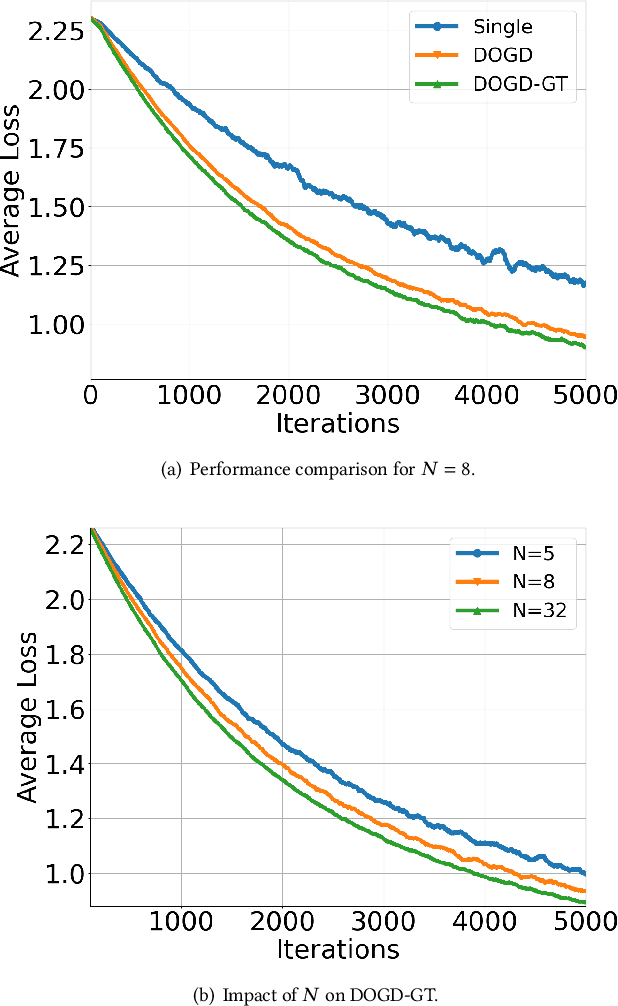
Online meta-learning is emerging as an enabling technique for achieving edge intelligence in the IoT ecosystem. Nevertheless, to learn a good meta-model for within-task fast adaptation, a single agent alone has to learn over many tasks, and this is the so-called 'cold-start' problem. Observing that in a multi-agent network the learning tasks across different agents often share some model similarity, we ask the following fundamental question: "Is it possible to accelerate the online meta-learning across agents via limited communication and if yes how much benefit can be achieved? " To answer this question, we propose a multi-agent online meta-learning framework and cast it as an equivalent two-level nested online convex optimization (OCO) problem. By characterizing the upper bound of the agent-task-averaged regret, we show that the performance of multi-agent online meta-learning depends heavily on how much an agent can benefit from the distributed network-level OCO for meta-model updates via limited communication, which however is not well understood. To tackle this challenge, we devise a distributed online gradient descent algorithm with gradient tracking where each agent tracks the global gradient using only one communication step with its neighbors per iteration, and it results in an average regret $O(\sqrt{T/N})$ per agent, indicating that a factor of $\sqrt{1/N}$ speedup over the optimal single-agent regret $O(\sqrt{T})$ after $T$ iterations, where $N$ is the number of agents. Building on this sharp performance speedup, we next develop a multi-agent online meta-learning algorithm and show that it can achieve the optimal task-average regret at a faster rate of $O(1/\sqrt{NT})$ via limited communication, compared to single-agent online meta-learning. Extensive experiments corroborate the theoretic results.