 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
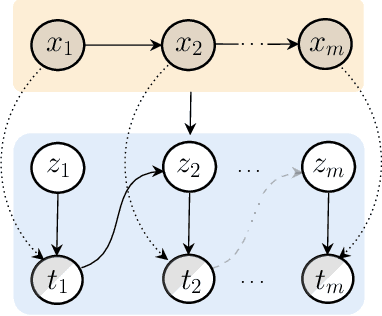
Add to EdgeSemantically-informed Hierarchical Event Modeling
Dec 20, 2022



Prior work has shown that coupling sequential latent variable models with semantic ontological knowledge can improve the representational capabilities of event modeling approaches. In this work, we present a novel, doubly hierarchical, semi-supervised event modeling framework that provides structural hierarchy while also accounting for ontological hierarchy. Our approach consists of multiple layers of structured latent variables, where each successive layer compresses and abstracts the previous layers. We guide this compression through the injection of structured ontological knowledge that is defined at the type level of events: importantly, our model allows for partial injection of semantic knowledge and it does not depend on observing instances at any particular level of the semantic ontology. Across two different datasets and four different evaluation metrics, we demonstrate that our approach is able to out-perform the previous state-of-the-art approaches, demonstrating the benefits of structured and semantic hierarchical knowledge for event modeling.
RevUp: Revise and Update Information Bottleneck for Event Representation
May 24, 2022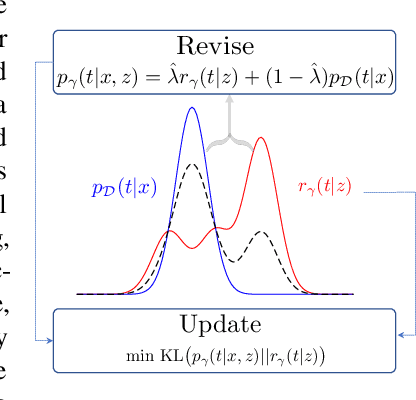

In machine learning, latent variables play a key role to capture the underlying structure of data, but they are often unsupervised. When we have side knowledge that already has high-level information about the input data, we can use that source to guide latent variables and capture the available background information in a process called "parameter injection." In that regard, we propose a semi-supervised information bottleneck-based model that enables the use of side knowledge, even if it is noisy and imperfect, to direct the learning of discrete latent variables. Fundamentally, we introduce an auxiliary continuous latent variable as a way to reparameterize the model's discrete variables with a light-weight hierarchical structure. With this reparameterization, the model's discrete latent variables are learned to minimize the mutual information between the observed data and optional side knowledge that is not already captured by the new, auxiliary variables. We theoretically show that our approach generalizes an existing method of parameter injection, and perform an empirical case study of our approach on language-based event modeling. We corroborate our theoretical results with strong empirical experiments, showing that the proposed method outperforms previous proposed approaches on multiple datasets.
Discriminative and Generative Transformer-based Models For Situation Entity Classification
Sep 15, 2021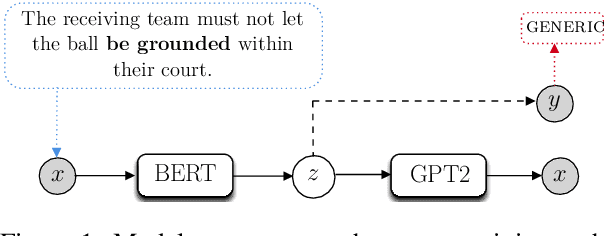
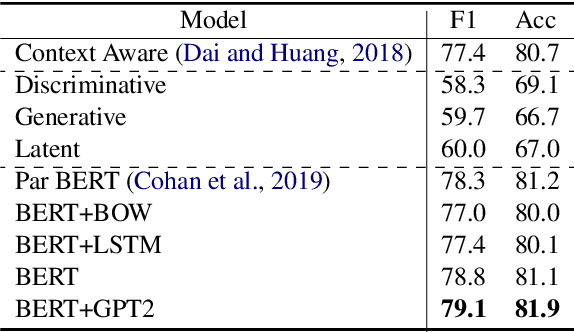
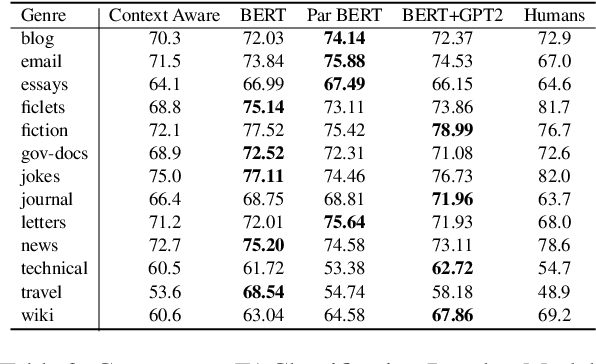
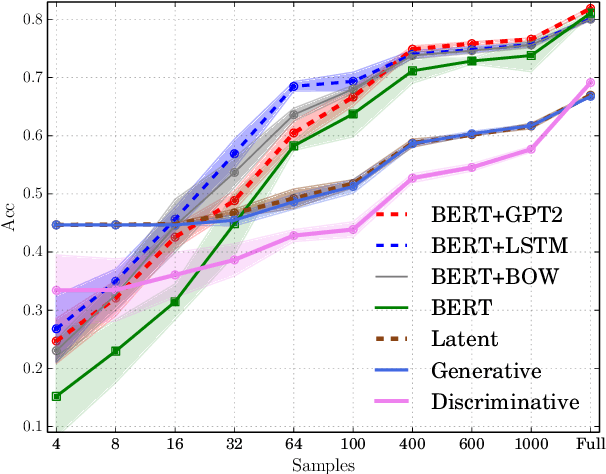
We re-examine the situation entity (SE) classification task with varying amounts of available training data. We exploit a Transformer-based variational autoencoder to encode sentences into a lower dimensional latent space, which is used to generate the text and learn a SE classifier. Test set and cross-genre evaluations show that when training data is plentiful, the proposed model can improve over the previous discriminative state-of-the-art models. Our approach performs disproportionately better with smaller amounts of training data, but when faced with extremely small sets (4 instances per label), generative RNN methods outperform transformers. Our work provides guidance for future efforts on SE and semantic prediction tasks, and low-label training regimes.
A Discrete Variational Recurrent Topic Model without the Reparametrization Trick
Oct 22, 2020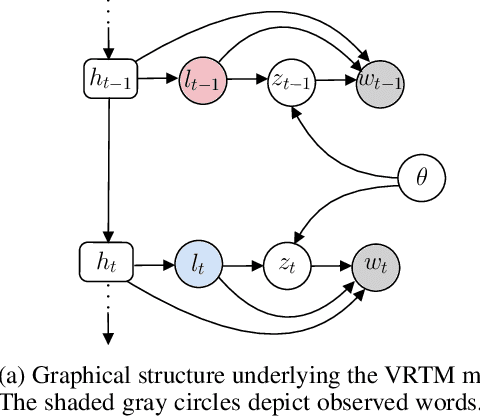
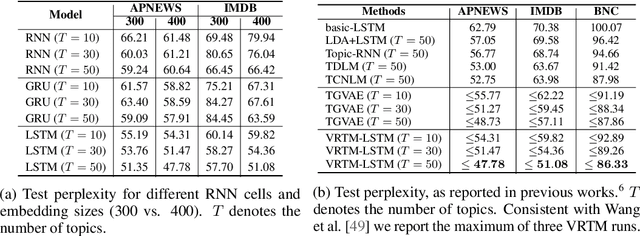
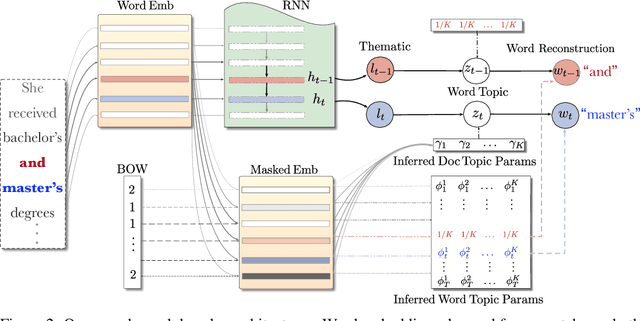
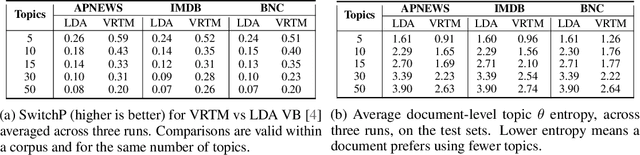
We show how to learn a neural topic model with discrete random variables---one that explicitly models each word's assigned topic---using neural variational inference that does not rely on stochastic backpropagation to handle the discrete variables. The model we utilize combines the expressive power of neural methods for representing sequences of text with the topic model's ability to capture global, thematic coherence. Using neural variational inference, we show improved perplexity and document understanding across multiple corpora. We examine the effect of prior parameters both on the model and variational parameters and demonstrate how our approach can compete and surpass a popular topic model implementation on an automatic measure of topic quality.
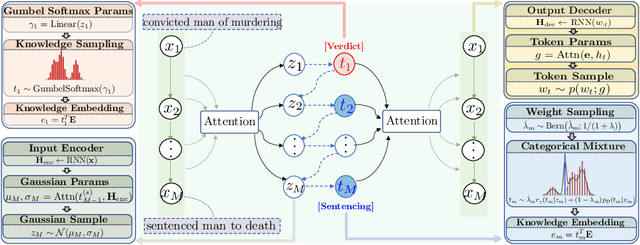
Event Representation with Sequential, Semi-Supervised Discrete Variables
Oct 16, 2020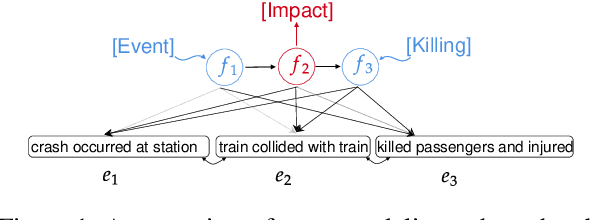
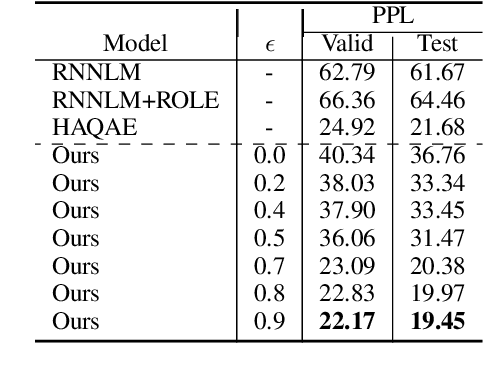
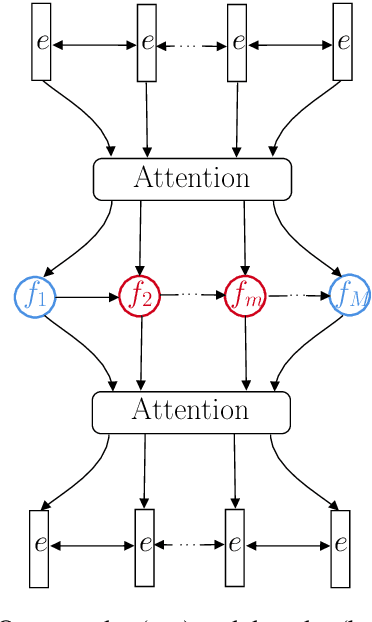
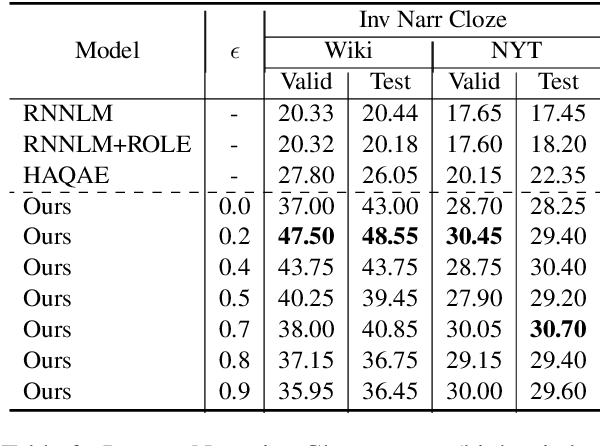
Within the context of event modeling and understanding, we propose a new method for neural sequence modeling that takes partially-observed sequences of discrete, external knowledge into account. We construct a sequential, neural variational autoencoder that uses a carefully defined encoder, and Gumbel-Softmax reparametrization, to allow for successful backpropagation during training. We show that our approach outperforms multiple baselines and the state-of-the-art in narrative script induction on multiple event modeling tasks. We demonstrate that our approach converges more quickly.