 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPINN-ABPI: Physics-Informed Neural Networks for Accurate Power Estimation in MPSoCs
May 28, 2025



Efficient thermal and power management in modern multiprocessor systems-on-chip (MPSoCs) demands accurate power consumption estimation. One of the state-of-the-art approaches, Alternative Blind Power Identification (ABPI), theoretically eliminates the dependence on steady-state temperatures, addressing a major shortcoming of previous approaches. However, ABPI performance has remained unverified in actual hardware implementations. In this study, we conduct the first empirical validation of ABPI on commercial hardware using the NVIDIA Jetson Xavier AGX platform. Our findings reveal that, while ABPI provides computational efficiency and independence from steady-state temperature, it exhibits considerable accuracy deficiencies in real-world scenarios. To overcome these limitations, we introduce a novel approach that integrates Custom Physics-Informed Neural Networks (CPINNs) with the underlying thermal model of ABPI. Our approach employs a specialized loss function that harmonizes physical principles with data-driven learning, complemented by multi-objective genetic algorithm optimization to balance estimation accuracy and computational cost. In experimental validation, CPINN-ABPI achieves a reduction of 84.7\% CPU and 73.9\% GPU in the mean absolute error (MAE) relative to ABPI, with the weighted mean absolute percentage error (WMAPE) improving from 47\%--81\% to $\sim$12\%. The method maintains real-time performance with 195.3~$\mu$s of inference time, with similar 85\%--99\% accuracy gains across heterogeneous SoCs.
Cluster-BPI: Efficient Fine-Grain Blind Power Identification for Defending against Hardware Thermal Trojans in Multicore SoCs
Sep 27, 2024



Modern multicore System-on-Chips (SoCs) feature hardware monitoring mechanisms that measure total power consumption. However, these aggregate measurements are often insufficient for fine-grained thermal and power management. This paper presents an enhanced Clustering Blind Power Identification (ICBPI) approach, designed to improve the sensitivity and robustness of the traditional Blind Power Identification (BPI) method. BPI estimates the power consumption of individual cores and models the thermal behavior of an SoC using only thermal sensor data and total power measurements. The proposed ICBPI approach refines BPI's initialization process, particularly improving the non-negative matrix factorization (NNMF) step, which is critical to the accuracy of BPI. ICBPI introduces density-based spatial clustering of applications with noise (DBSCAN) to better align temperature and power consumption data, thereby providing more accurate power consumption estimates. We validate the ICBPI method through two key tasks. The first task evaluates power estimation accuracy across four different multicore architectures, including a heterogeneous processor. Results show that ICBPI significantly enhances accuracy, reducing error rates by 77.56% compared to the original BPI and by 68.44% compared to the state-of-the-art BPISS method. The second task focuses on improving the detection and localization of malicious thermal sensor attacks in heterogeneous processors. The results demonstrate that ICBPI enhances the security and robustness of multicore SoCs against such attacks.
A Survey on Popularity Bias in Recommender Systems
Aug 11, 2023Recommender systems help people find relevant content in a personalized way. One main promise of such systems is that they are able to increase the visibility of items in the long tail, i.e., the lesser-known items in a catalogue. Existing research, however, suggests that in many situations today's recommendation algorithms instead exhibit a popularity bias, meaning that they often focus on rather popular items in their recommendations. Such a bias may not only lead to limited value of the recommendations for consumers and providers in the short run, but it may also cause undesired reinforcement effects over time. In this paper, we discuss the potential reasons for popularity bias and we review existing approaches to detect, quantify and mitigate popularity bias in recommender systems. Our survey therefore includes both an overview of the computational metrics used in the literature as well as a review of the main technical approaches to reduce the bias. We furthermore critically discuss today's literature, where we observe that the research is almost entirely based on computational experiments and on certain assumptions regarding the practical effects of including long-tail items in the recommendations.
Social Network based Short-Term Stock Trading System
Jan 16, 2018

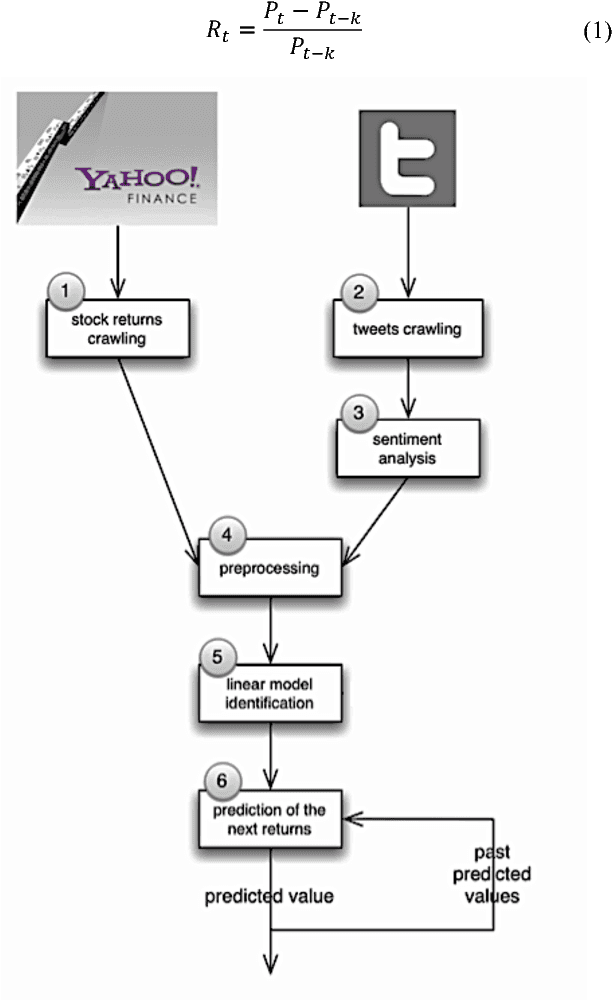
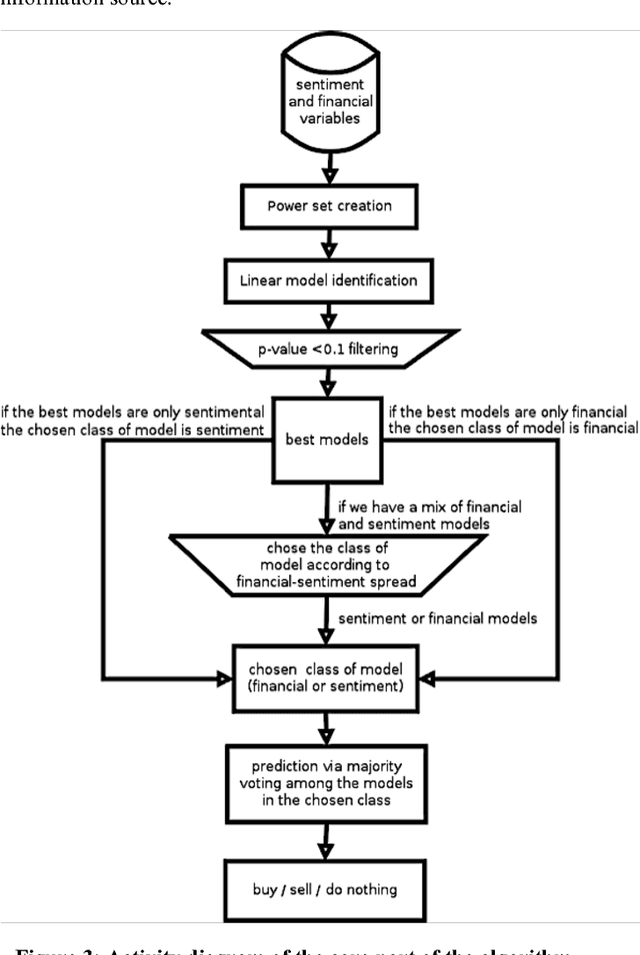
This paper proposes a novel adaptive algorithm for the automated short-term trading of financial instrument. The algorithm adopts a semantic sentiment analysis technique to inspect the Twitter posts and to use them to predict the behaviour of the stock market. Indeed, the algorithm is specifically developed to take advantage of both the sentiment and the past values of a certain financial instrument in order to choose the best investment decision. This allows the algorithm to ensure the maximization of the obtainable profits by trading on the stock market. We have conducted an investment simulation and compared the performance of our proposed with a well-known benchmark (DJTATO index) and the optimal results, in which an investor knows in advance the future price of a product. The result shows that our approach outperforms the benchmark and achieves the performance score close to the optimal result.
Using Mise-En-Scène Visual Features based on MPEG-7 and Deep Learning for Movie Recommendation
Apr 20, 2017



Item features play an important role in movie recommender systems, where recommendations can be generated by using explicit or implicit preferences of users on traditional features (attributes) such as tag, genre, and cast. Typically, movie features are human-generated, either editorially (e.g., genre and cast) or by leveraging the wisdom of the crowd (e.g., tag), and as such, they are prone to noise and are expensive to collect. Moreover, these features are often rare or absent for new items, making it difficult or even impossible to provide good quality recommendations. In this paper, we show that user's preferences on movies can be better described in terms of the mise-en-sc\`ene features, i.e., the visual aspects of a movie that characterize design, aesthetics and style (e.g., colors, textures). We use both MPEG-7 visual descriptors and Deep Learning hidden layers as example of mise-en-sc\`ene features that can visually describe movies. Interestingly, mise-en-sc\`ene features can be computed automatically from video files or even from trailers, offering more flexibility in handling new items, avoiding the need for costly and error-prone human-based tagging, and providing good scalability. We have conducted a set of experiments on a large catalogue of 4K movies. Results show that recommendations based on mise-en-sc\`ene features consistently provide the best performance with respect to richer sets of more traditional features, such as genre and tag.