 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Answerability of LLMs for Long-Form Question Answering
Sep 15, 2023As we embark on a new era of LLMs, it becomes increasingly crucial to understand their capabilities, limitations, and differences. Toward making further progress in this direction, we strive to build a deeper understanding of the gaps between massive LLMs (e.g., ChatGPT) and smaller yet effective open-source LLMs and their distilled counterparts. To this end, we specifically focus on long-form question answering (LFQA) because it has several practical and impactful applications (e.g., troubleshooting, customer service, etc.) yet is still understudied and challenging for LLMs. We propose a question-generation method from abstractive summaries and show that generating follow-up questions from summaries of long documents can create a challenging setting for LLMs to reason and infer from long contexts. Our experimental results confirm that: (1) our proposed method of generating questions from abstractive summaries pose a challenging setup for LLMs and shows performance gaps between LLMs like ChatGPT and open-source LLMs (Alpaca, Llama) (2) open-source LLMs exhibit decreased reliance on context for generated questions from the original document, but their generation capabilities drop significantly on generated questions from summaries -- especially for longer contexts (>1024 tokens)
Self-training with Few-shot Rationalization: Teacher Explanations Aid Student in Few-shot NLU
Sep 17, 2021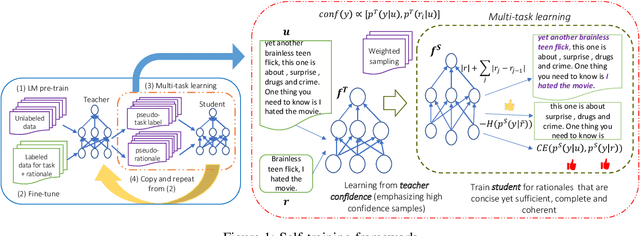

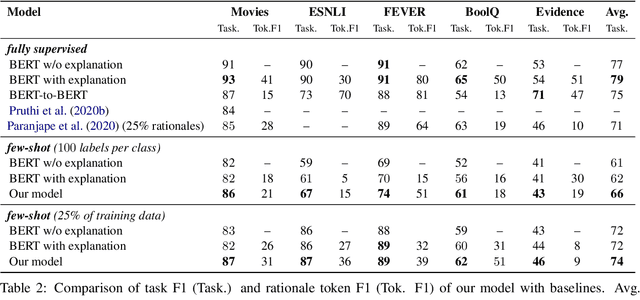

While pre-trained language models have obtained state-of-the-art performance for several natural language understanding tasks, they are quite opaque in terms of their decision-making process. While some recent works focus on rationalizing neural predictions by highlighting salient concepts in the text as justifications or rationales, they rely on thousands of labeled training examples for both task labels as well as an-notated rationales for every instance. Such extensive large-scale annotations are infeasible to obtain for many tasks. To this end, we develop a multi-task teacher-student framework based on self-training language models with limited task-specific labels and rationales, and judicious sample selection to learn from informative pseudo-labeled examples1. We study several characteristics of what constitutes a good rationale and demonstrate that the neural model performance can be significantly improved by making it aware of its rationalized predictions, particularly in low-resource settings. Extensive experiments in several bench-mark datasets demonstrate the effectiveness of our approach.