 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBank Loan Prediction Using Machine Learning Techniques
Oct 11, 2024

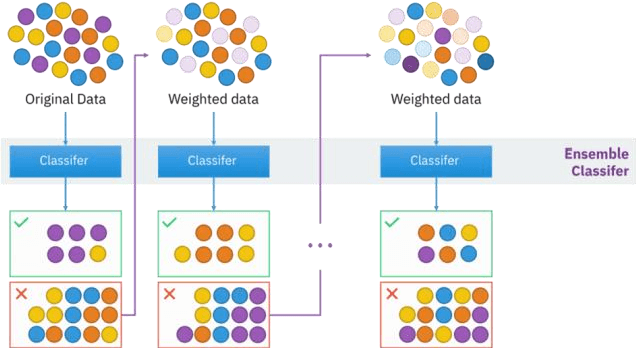

Banks are important for the development of economies in any financial ecosystem through consumer and business loans. Lending, however, presents risks; thus, banks have to determine the applicant's financial position to reduce the probabilities of default. A number of banks have currently, therefore, adopted data analytics and state-of-the-art technology to arrive at better decisions in the process. The probability of payback is prescribed by a predictive modeling technique in which machine learning algorithms are applied. In this research project, we will apply several machine learning methods to further improve the accuracy and efficiency of loan approval processes. Our work focuses on the prediction of bank loan approval; we have worked on a dataset of 148,670 instances and 37 attributes using machine learning methods. The target property segregates the loan applications into "Approved" and "Denied" groups. various machine learning techniques have been used, namely, Decision Tree Categorization, AdaBoosting, Random Forest Classifier, SVM, and GaussianNB. Following that, the models were trained and evaluated. Among these, the best-performing algorithm was AdaBoosting, which achieved an incredible accuracy of 99.99%. The results therefore show how ensemble learning works effectively to improve the prediction skills of loan approval decisions. The presented work points to the possibility of achieving extremely accurate and efficient loan prediction models that provide useful insights for applying machine learning to financial domains.
Enhancing Bangla Fake News Detection Using Bidirectional Gated Recurrent Units and Deep Learning Techniques
Mar 31, 2024The rise of fake news has made the need for effective detection methods, including in languages other than English, increasingly important. The study aims to address the challenges of Bangla which is considered a less important language. To this end, a complete dataset containing about 50,000 news items is proposed. Several deep learning models have been tested on this dataset, including the bidirectional gated recurrent unit (GRU), the long short-term memory (LSTM), the 1D convolutional neural network (CNN), and hybrid architectures. For this research, we assessed the efficacy of the model utilizing a range of useful measures, including recall, precision, F1 score, and accuracy. This was done by employing a big application. We carry out comprehensive trials to show the effectiveness of these models in identifying bogus news in Bangla, with the Bidirectional GRU model having a stunning accuracy of 99.16%. Our analysis highlights the importance of dataset balance and the need for continual improvement efforts to a substantial degree. This study makes a major contribution to the creation of Bangla fake news detecting systems with limited resources, thereby setting the stage for future improvements in the detection process.