 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding and Improving GFlowNet Training
May 11, 2023


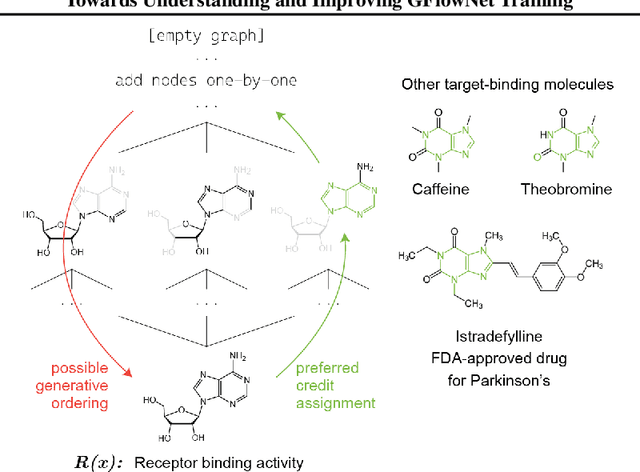
Generative flow networks (GFlowNets) are a family of algorithms that learn a generative policy to sample discrete objects $x$ with non-negative reward $R(x)$. Learning objectives guarantee the GFlowNet samples $x$ from the target distribution $p^*(x) \propto R(x)$ when loss is globally minimized over all states or trajectories, but it is unclear how well they perform with practical limits on training resources. We introduce an efficient evaluation strategy to compare the learned sampling distribution to the target reward distribution. As flows can be underdetermined given training data, we clarify the importance of learned flows to generalization and matching $p^*(x)$ in practice. We investigate how to learn better flows, and propose (i) prioritized replay training of high-reward $x$, (ii) relative edge flow policy parametrization, and (iii) a novel guided trajectory balance objective, and show how it can solve a substructure credit assignment problem. We substantially improve sample efficiency on biochemical design tasks.
Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient
Feb 10, 2022The problem of human trust in artificial intelligence is one of the most fundamental problems in applied machine learning. Our processes for evaluating AI trustworthiness have substantial ramifications for ML's impact on science, health, and humanity, yet confusion surrounds foundational concepts. What does it mean to trust an AI, and how do humans assess AI trustworthiness? What are the mechanisms for building trustworthy AI? And what is the role of interpretable ML in trust? Here, we draw from statistical learning theory and sociological lenses on human-automation trust to motivate an AI-as-tool framework, which distinguishes human-AI trust from human-AI-human trust. Evaluating an AI's contractual trustworthiness involves predicting future model behavior using behavior certificates (BCs) that aggregate behavioral evidence from diverse sources including empirical out-of-distribution and out-of-task evaluation and theoretical proofs linking model architecture to behavior. We clarify the role of interpretability in trust with a ladder of model access. Interpretability (level 3) is not necessary or even sufficient for trust, while the ability to run a black-box model at-will (level 2) is necessary and sufficient. While interpretability can offer benefits for trust, it can also incur costs. We clarify ways interpretability can contribute to trust, while questioning the perceived centrality of interpretability to trust in popular discourse. How can we empower people with tools to evaluate trust? Instead of trying to understand how a model works, we argue for understanding how a model behaves. Instead of opening up black boxes, we should create more behavior certificates that are more correct, relevant, and understandable. We discuss how to build trusted and trustworthy AI responsibly.