 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Learning of Bounded-Treewidth Bayesian Networks from Complete and Incomplete Data Sets
Feb 07, 2018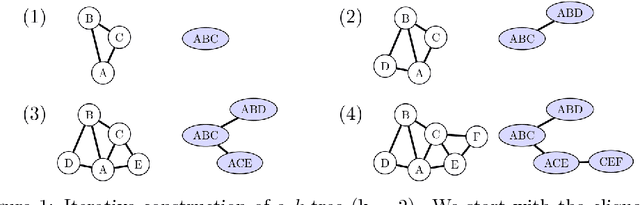
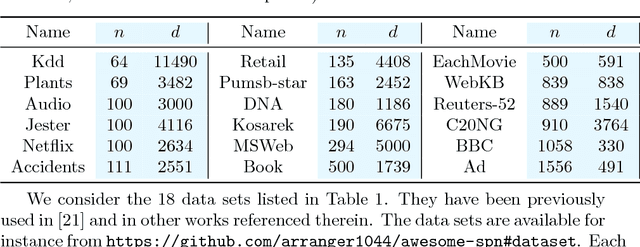
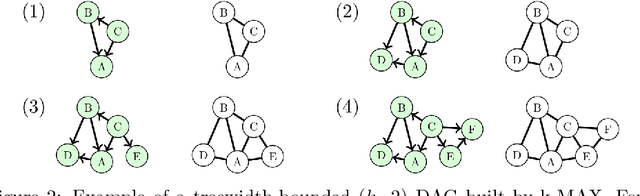
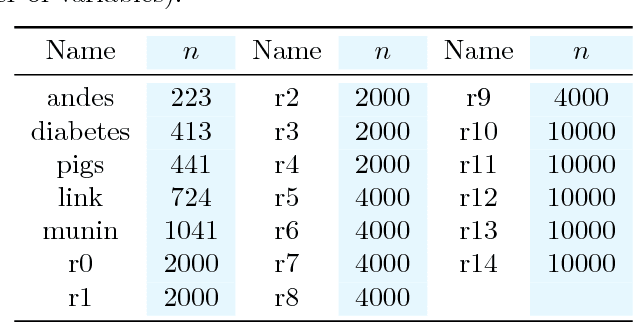
Learning a Bayesian networks with bounded treewidth is important for reducing the complexity of the inferences. We present a novel anytime algorithm (k-MAX) method for this task, which scales up to thousands of variables. Through extensive experiments we show that it consistently yields higher-scoring structures than its competitors on complete data sets. We then consider the problem of structure learning from incomplete data sets. This can be addressed by structural EM, which however is computationally very demanding. We thus adopt the novel k-MAX algorithm in the maximization step of structural EM, obtaining an efficient computation of the expected sufficient statistics. We test the resulting structural EM method on the task of imputing missing data, comparing it against the state-of-the-art approach based on random forests. Our approach achieves the same imputation accuracy of the competitors, but in about one tenth of the time. Furthermore we show that it has worst-case complexity linear in the input size, and that it is easily parallelizable.
Entropy-based Pruning for Learning Bayesian Networks using BIC
Jul 19, 2017


For decomposable score-based structure learning of Bayesian networks, existing approaches first compute a collection of candidate parent sets for each variable and then optimize over this collection by choosing one parent set for each variable without creating directed cycles while maximizing the total score. We target the task of constructing the collection of candidate parent sets when the score of choice is the Bayesian Information Criterion (BIC). We provide new non-trivial results that can be used to prune the search space of candidate parent sets of each node. We analyze how these new results relate to previous ideas in the literature both theoretically and empirically. We show in experiments with UCI data sets that gains can be significant. Since the new pruning rules are easy to implement and have low computational costs, they can be promptly integrated into all state-of-the-art methods for structure learning of Bayesian networks.
Learning Bounded Treewidth Bayesian Networks with Thousands of Variables
May 11, 2016



We present a method for learning treewidth-bounded Bayesian networks from data sets containing thousands of variables. Bounding the treewidth of a Bayesian greatly reduces the complexity of inferences. Yet, being a global property of the graph, it considerably increases the difficulty of the learning process. We propose a novel algorithm for this task, able to scale to large domains and large treewidths. Our novel approach consistently outperforms the state of the art on data sets with up to ten thousand variables.