 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning the burn-in phase in training recurrent neural networks improves their performance
Feb 11, 2026Training recurrent neural networks (RNNs) with standard backpropagation through time (BPTT) can be challenging, especially in the presence of long input sequences. A practical alternative to reduce computational and memory overhead is to perform BPTT repeatedly over shorter segments of the training data set, corresponding to truncated BPTT. In this paper, we examine the training of RNNs when using such a truncated learning approach for time series tasks. Specifically, we establish theoretical bounds on the accuracy and performance loss when optimizing over subsequences instead of the full data sequence. This reveals that the burn-in phase of the RNN is an important tuning knob in its training, with significant impact on the performance guarantees. We validate our theoretical results through experiments on standard benchmarks from the fields of system identification and time series forecasting. In all experiments, we observe a strong influence of the burn-in phase on the training process, and proper tuning can lead to a reduction of the prediction error on the training and test data of more than 60% in some cases.
Low-Rank Matrix Regression via Least-Angle Regression
Mar 13, 2025



Low-rank matrix regression is a fundamental problem in data science with various applications in systems and control. Nuclear norm regularization has been widely applied to solve this problem due to its convexity. However, it suffers from high computational complexity and the inability to directly specify the rank. This work introduces a novel framework for low-rank matrix regression that addresses both unstructured and Hankel matrices. By decomposing the low-rank matrix into rank-1 bases, the problem is reformulated as an infinite-dimensional sparse learning problem. The least-angle regression (LAR) algorithm is then employed to solve this problem efficiently. For unstructured matrices, a closed-form LAR solution is derived with equivalence to a normalized nuclear norm regularization problem. For Hankel matrices, a real-valued polynomial basis reformulation enables effective LAR implementation. Two numerical examples in network modeling and system realization demonstrate that the proposed approach significantly outperforms the nuclear norm method in terms of estimation accuracy and computational efficiency.
Gaussian Process-Based Prediction and Control of Hammerstein-Wiener Systems
Jan 27, 2025This work investigates data-driven prediction and control of Hammerstein-Wiener systems using physics-informed Gaussian process models. Data-driven prediction algorithms have been developed for structured nonlinear systems based on Willems' fundamental lemma. However, existing frameworks cannot treat output nonlinearities and require a dictionary of basis functions for Hammerstein systems. In this work, an implicit predictor structure is considered, leveraging the multi-step-ahead ARX structure for the linear part of the model. This implicit function is learned by Gaussian process regression with kernel functions designed from Gaussian process priors for the nonlinearities. The linear model parameters are estimated as hyperparameters by assuming a stable spline hyperprior. The implicit Gaussian process model provides explicit output prediction by optimizing selected optimality criteria. The model is also applied to receding horizon control with the expected control cost and chance constraint satisfaction guarantee. Numerical results demonstrate that the proposed prediction and control algorithms are superior to black-box Gaussian process models.
An Efficient Off-Policy Reinforcement Learning Algorithm for the Continuous-Time LQR Problem
Mar 31, 2023In this paper, an off-policy reinforcement learning algorithm is designed to solve the continuous-time LQR problem using only input-state data measured from the system. Different from other algorithms in the literature, we propose the use of a specific persistently exciting input as the exploration signal during the data collection step. We then show that, using this persistently excited data, the solution of the matrix equation in our algorithm is guaranteed to exist and to be unique at every iteration. Convergence of the algorithm to the optimal control input is also proven. Moreover, we formulate the policy evaluation step as the solution of a Sylvester-transpose equation, which increases the efficiency of its solution. Finally, a method to determine a stabilizing policy to initialize the algorithm using only measured data is proposed.
Informed Circular Fields for Global Reactive Obstacle Avoidance of Robotic Manipulators
Dec 12, 2022

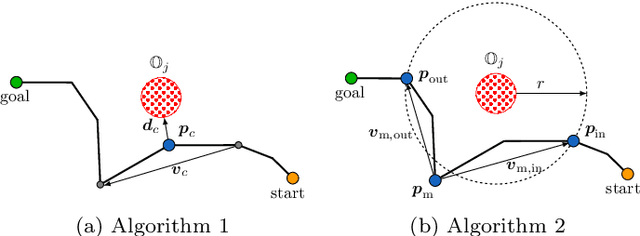
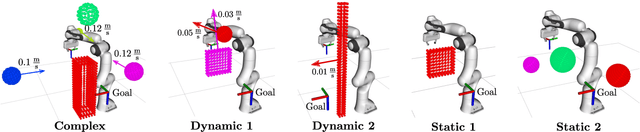
In this paper a global reactive motion planning framework for robotic manipulators in complex dynamic environments is presented. In particular, the circular field predictions (CFP) planner from Becker et al. (2021) is extended to ensure obstacle avoidance of the whole structure of a robotic manipulator. Towards this end, a motion planning framework is developed that leverages global information about promising avoidance directions from arbitrary configuration space motion planners, resulting in improved global trajectories while reactively avoiding dynamic obstacles and decreasing the required computational power. The resulting motion planning framework is tested in multiple simulations with complex and dynamic obstacles and demonstrates great potential compared to existing motion planning approaches.
Motion Planning using Reactive Circular Fields: A 2D Analysis of Collision Avoidance and Goal Convergence
Oct 28, 2022Recently, many reactive trajectory planning approaches were suggested in the literature because of their inherent immediate adaption in the ever more demanding cluttered and unpredictable environments of robotic systems. However, typically those approaches are only locally reactive without considering global path planning and no guarantees for simultaneous collision avoidance and goal convergence can be given. In this paper, we study a recently developed circular field (CF)-based motion planner that combines local reactive control with global trajectory generation by adapting an artificial magnetic field such that multiple trajectories around obstacles can be evaluated. In particular, we provide a mathematically rigorous analysis of this planner in a planar environment to ensure safe motion of the controlled robot. Contrary to existing results, the derived collision avoidance analysis covers the entire CF motion planning algorithm including attractive forces for goal convergence and is not limited to a specific choice of the rotation field, i.e., our guarantees are not limited to a specific potentially suboptimal trajectory. Our Lyapunov-type collision avoidance analysis is based on the definition of an (equivalent) two-dimensional auxiliary system, which enables us to provide tight, if and only if conditions for the case of a collision with point obstacles. Furthermore, we show how this analysis naturally extends to multiple obstacles and we specify sufficient conditions for goal convergence. Finally, we provide a challenging simulation scenario with multiple non-convex point cloud obstacles and demonstrate collision avoidance and goal convergence.