 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-wise Constrained Learning via a Sequential Penalty Approach with Applications in Image Processing
Jan 23, 2026In many learning tasks, certain requirements on the processing of individual data samples should arguably be formalized as strict constraints in the underlying optimization problem, rather than by means of arbitrary penalties. We show that, in these scenarios, learning can be carried out exploiting a sequential penalty method that allows to properly deal with constraints. The proposed algorithm is shown to possess convergence guarantees under assumptions that are reasonable in deep learning scenarios. Moreover, the results of experiments on image processing tasks show that the method is indeed viable to be used in practice.
Optimization-Driven Design of Monolithic Soft-Rigid Grippers
Dec 10, 2024

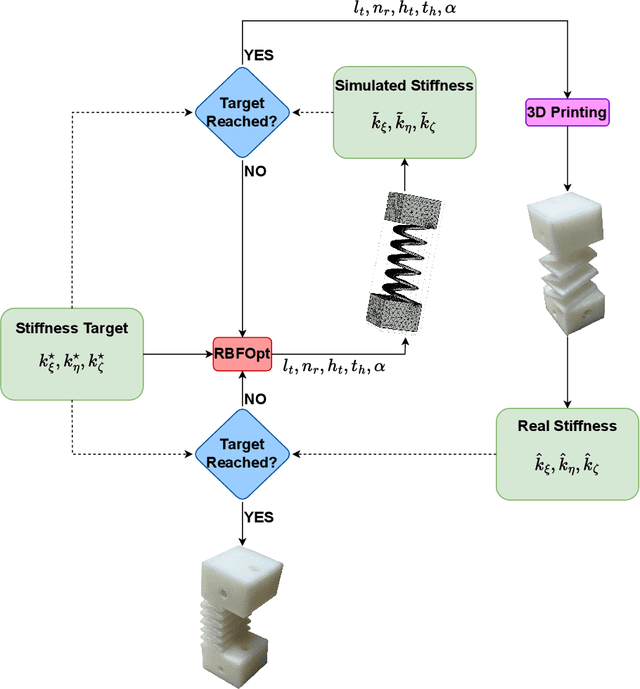
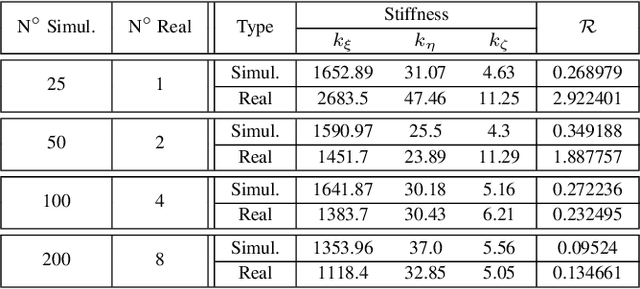
Sim-to-real transfer remains a significant challenge in soft robotics due to the unpredictability introduced by common manufacturing processes such as 3D printing and molding. These processes often result in deviations from simulated designs, requiring multiple prototypes before achieving a functional system. In this study, we propose a novel methodology to address these limitations by combining advanced rapid prototyping techniques and an efficient optimization strategy. Firstly, we employ rapid prototyping methods typically used for rigid structures, leveraging their precision to fabricate compliant components with reduced manufacturing errors. Secondly, our optimization framework minimizes the need for extensive prototyping, significantly reducing the iterative design process. The methodology enables the identification of stiffness parameters that are more practical and achievable within current manufacturing capabilities. The proposed approach demonstrates a substantial improvement in the efficiency of prototype development while maintaining the desired performance characteristics. This work represents a step forward in bridging the sim-to-real gap in soft robotics, paving the way towards a faster and more reliable deployment of soft robotic systems.
Effectively Leveraging Momentum Terms in Stochastic Line Search Frameworks for Fast Optimization of Finite-Sum Problems
Nov 11, 2024In this work, we address unconstrained finite-sum optimization problems, with particular focus on instances originating in large scale deep learning scenarios. Our main interest lies in the exploration of the relationship between recent line search approaches for stochastic optimization in the overparametrized regime and momentum directions. First, we point out that combining these two elements with computational benefits is not straightforward. To this aim, we propose a solution based on mini-batch persistency. We then introduce an algorithmic framework that exploits a mix of data persistency, conjugate-gradient type rules for the definition of the momentum parameter and stochastic line searches. The resulting algorithm is empirically shown to outperform other popular methods from the literature, obtaining state-of-the-art results in both convex and nonconvex large scale training problems.
Convergence Conditions for Stochastic Line Search Based Optimization of Over-parametrized Models
Aug 06, 2024In this paper, we deal with algorithms to solve the finite-sum problems related to fitting over-parametrized models, that typically satisfy the interpolation condition. In particular, we focus on approaches based on stochastic line searches and employing general search directions. We define conditions on the sequence of search directions that guarantee finite termination and bounds for the backtracking procedure. Moreover, we shed light on the additional property of directions needed to prove fast (linear) convergence of the general class of algorithms when applied to PL functions in the interpolation regime. From the point of view of algorithms design, the proposed analysis identifies safeguarding conditions that could be employed in relevant algorithmic framework. In particular, it could be of interest to integrate stochastic line searches within momentum, conjugate gradient or adaptive preconditioning methods.
Loss-Optimal Classification Trees: A Generalized Framework and the Logistic Case
Jun 01, 2023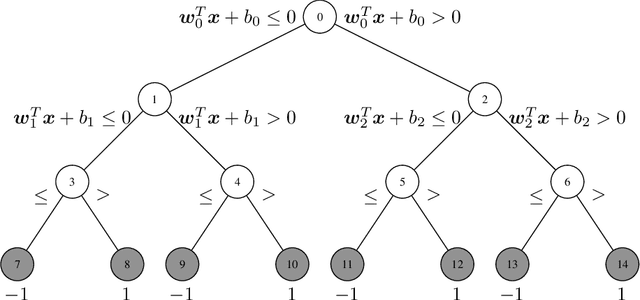

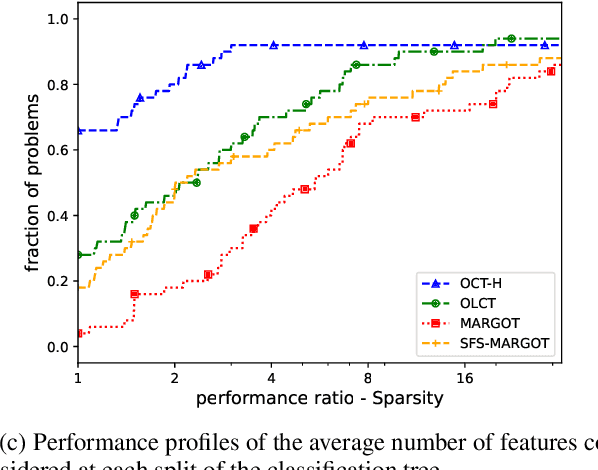
The Classification Tree (CT) is one of the most common models in interpretable machine learning. Although such models are usually built with greedy strategies, in recent years, thanks to remarkable advances in Mixer-Integer Programming (MIP) solvers, several exact formulations of the learning problem have been developed. In this paper, we argue that some of the most relevant ones among these training models can be encapsulated within a general framework, whose instances are shaped by the specification of loss functions and regularizers. Next, we introduce a novel realization of this framework: specifically, we consider the logistic loss, handled in the MIP setting by a linear piece-wise approximation, and couple it with $\ell_1$-regularization terms. The resulting Optimal Logistic Tree model numerically proves to be able to induce trees with enhanced interpretability features and competitive generalization capabilities, compared to the state-of-the-art MIP-based approaches.
A Robust Initialization of Residual Blocks for Effective ResNet Training without Batch Normalization
Dec 23, 2021
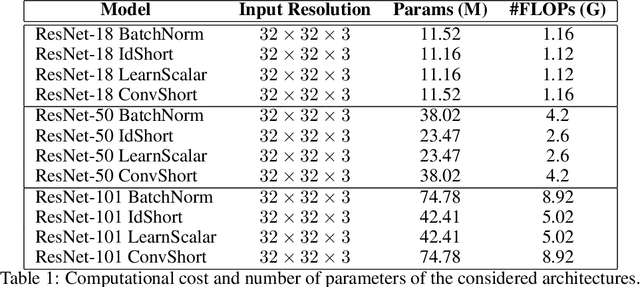
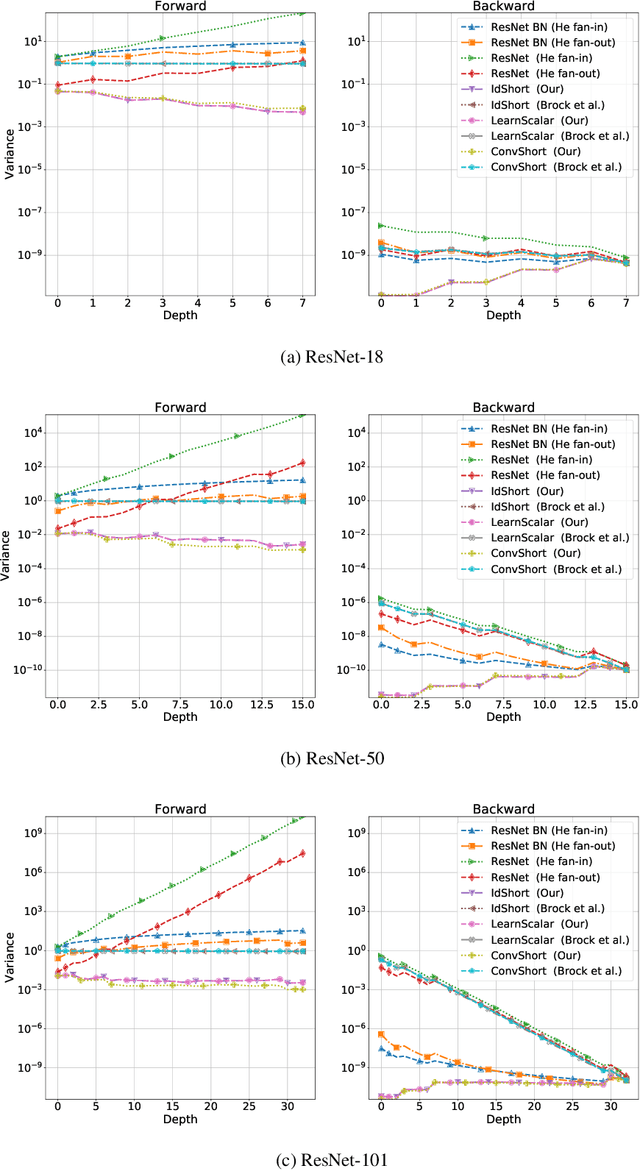
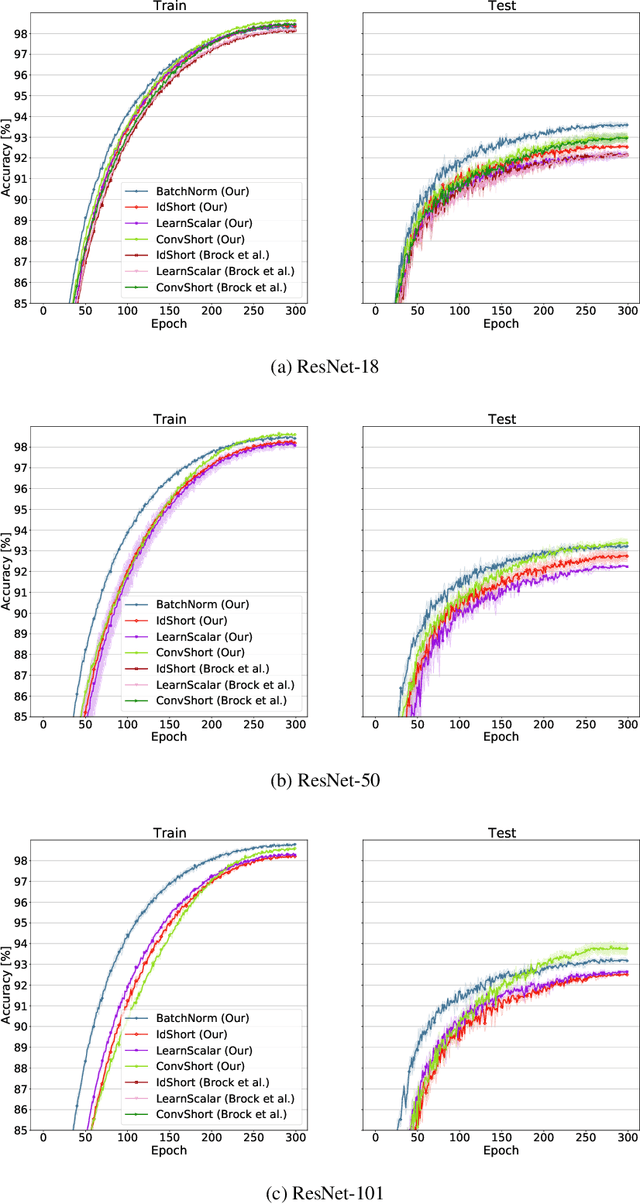
Batch Normalization is an essential component of all state-of-the-art neural networks architectures. However, since it introduces many practical issues, much recent research has been devoted to designing normalization-free architectures. In this paper, we show that weights initialization is key to train ResNet-like normalization-free networks. In particular, we propose a slight modification to the summation operation of a block output to the skip connection branch, so that the whole network is correctly initialized. We show that this modified architecture achieves competitive results on CIFAR-10 without further regularization nor algorithmic modifications.