 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss-Optimal Classification Trees: A Generalized Framework and the Logistic Case
Jun 01, 2023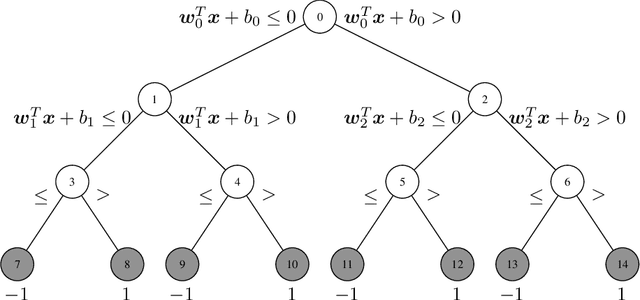

The Classification Tree (CT) is one of the most common models in interpretable machine learning. Although such models are usually built with greedy strategies, in recent years, thanks to remarkable advances in Mixer-Integer Programming (MIP) solvers, several exact formulations of the learning problem have been developed. In this paper, we argue that some of the most relevant ones among these training models can be encapsulated within a general framework, whose instances are shaped by the specification of loss functions and regularizers. Next, we introduce a novel realization of this framework: specifically, we consider the logistic loss, handled in the MIP setting by a linear piece-wise approximation, and couple it with $\ell_1$-regularization terms. The resulting Optimal Logistic Tree model numerically proves to be able to induce trees with enhanced interpretability features and competitive generalization capabilities, compared to the state-of-the-art MIP-based approaches.
A Novel Memetic Strategy for Optimized Learning of Classification Trees
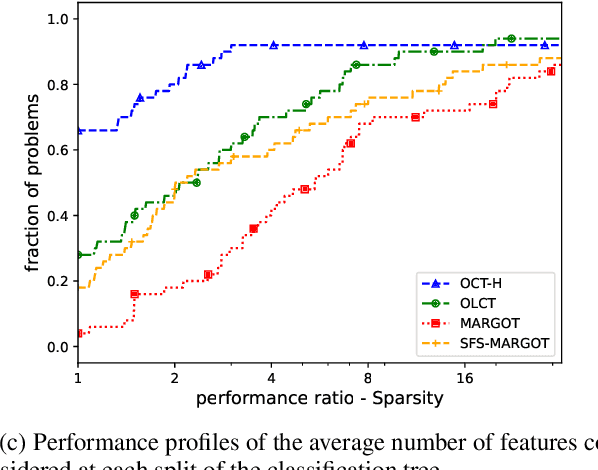
May 13, 2023Given the increasing interest in interpretable machine learning, classification trees have again attracted the attention of the scientific community because of their glass-box structure. These models are usually built using greedy procedures, solving subproblems to find cuts in the feature space that minimize some impurity measures. In contrast to this standard greedy approach and to the recent advances in the definition of the learning problem through MILP-based exact formulations, in this paper we propose a novel evolutionary algorithm for the induction of classification trees that exploits a memetic approach that is able to handle datasets with thousands of points. Our procedure combines the exploration of the feasible space of solutions with local searches to obtain structures with generalization capabilities that are competitive with the state-of-the-art methods.
Contextual Decision Trees
Jul 13, 2022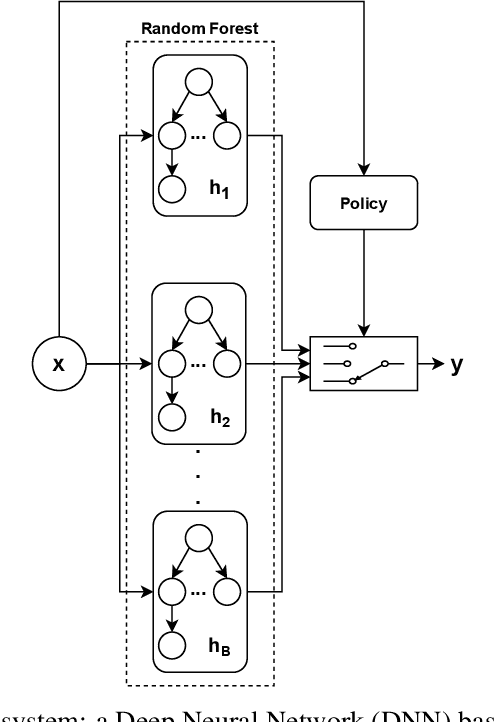
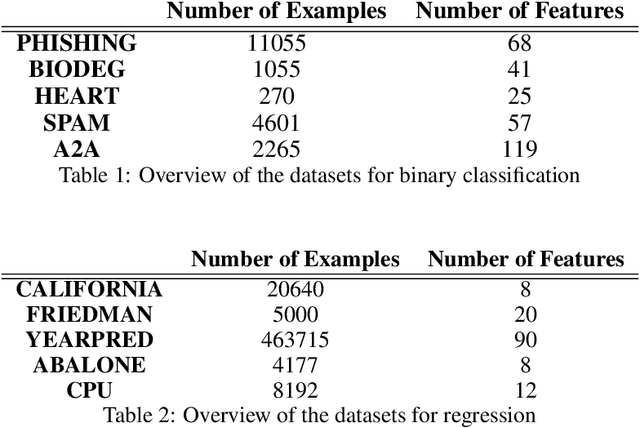
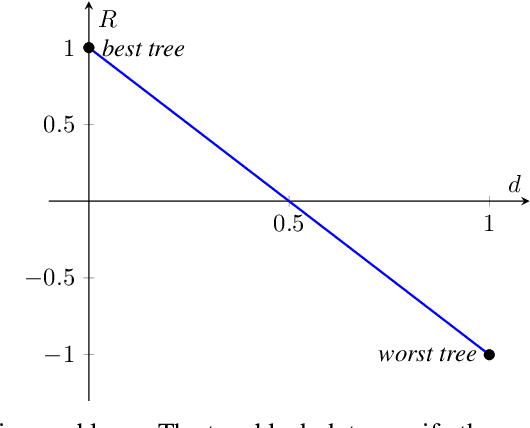

Focusing on Random Forests, we propose a multi-armed contextual bandit recommendation framework for feature-based selection of a single shallow tree of the learned ensemble. The trained system, which works on top of the Random Forest, dynamically identifies a base predictor that is responsible for providing the final output. In this way, we obtain local interpretations by observing the rules of the recommended tree. The carried out experiments reveal that our dynamic method is superior to an independent fitted CART decision tree and comparable to the whole black-box Random Forest in terms of predictive performances.