 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Channel and Semantic-aware Grouping for Effective Collaborative Edge Inference
Oct 02, 2025We focus on collaborative edge inference over wireless, which enables multiple devices to cooperate to improve inference performance in the presence of corrupted data. Exploiting a key-query mechanism for selective information exchange (or, group formation for collaboration), we recall the effect of wireless channel impairments in feature communication. We argue and show that a disjoint approach, which only considers either the semantic relevance or channel state between devices, performs poorly, especially in harsh propagation conditions. Based on these findings, we propose a joint approach that takes into account semantic information relevance and channel states when grouping devices for collaboration, by making the general attention weights dependent of the channel information. Numerical simulations show the superiority of the joint approach against local inference on corrupted data, as well as compared to collaborative inference with disjoint decisions that either consider application or physical layer parameters when forming groups.
Collaborative Edge Inference via Semantic Grouping under Wireless Channel Constraints
Oct 02, 2025


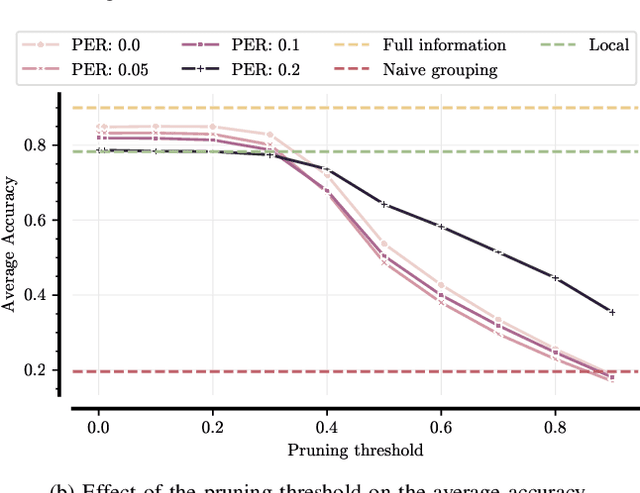
In this paper, we study the framework of collaborative inference, or edge ensembles. This framework enables multiple edge devices to improve classification accuracy by exchanging intermediate features rather than raw observations. However, efficient communication strategies are essential to balance accuracy and bandwidth limitations. Building upon a key-query mechanism for selective information exchange, this work extends collaborative inference by studying the impact of channel noise in feature communication, the choice of intermediate collaboration points, and the communication-accuracy trade-off across tasks. By analyzing how different collaboration points affect performance and exploring communication pruning, we show that it is possible to optimize accuracy while minimizing resource usage. We show that the intermediate collaboration approach is robust to channel errors and that the query transmission needs a higher degree of reliability than the data transmission itself.
Intent-Aware DRL-Based Uplink Dynamic Scheduler for 5G-NR
Mar 27, 2024



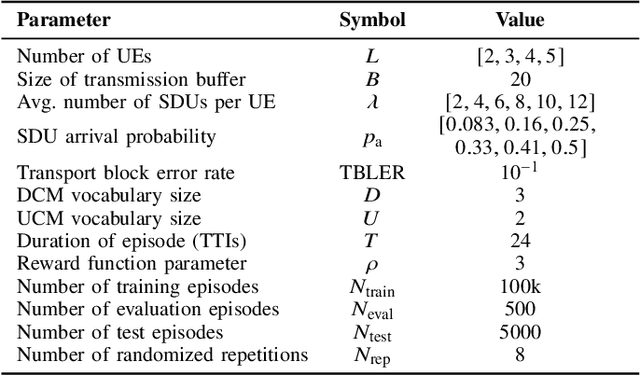
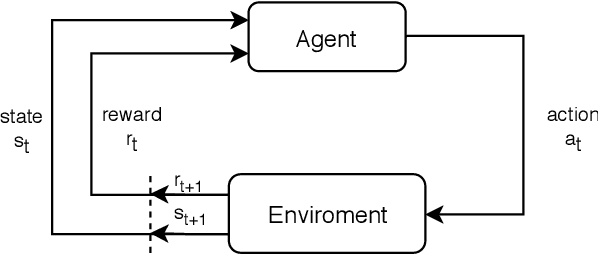
We investigate the problem of supporting Industrial Internet of Things user equipment (IIoT UEs) with intent (i.e., requested quality of service (QoS)) and random traffic arrival. A deep reinforcement learning (DRL) based centralized dynamic scheduler for time-frequency resources is proposed to learn how to schedule the available communication resources among the IIoT UEs. The proposed scheduler leverages an RL framework to adapt to the dynamic changes in the wireless communication system and traffic arrivals. Moreover, a graph-based reduction scheme is proposed to reduce the state and action space of the RL framework to allow fast convergence and a better learning strategy. Simulation results demonstrate the effectiveness of the proposed intelligent scheduler in guaranteeing the expressed intent of IIoT UEs compared to several traditional scheduling schemes, such as round-robin, semi-static, and heuristic approaches. The proposed scheduler also outperforms the contention-free and contention-based schemes in maximizing the number of successfully computed tasks.
Emergent Communication Protocol Learning for Task Offloading in Industrial Internet of Things
Jan 23, 2024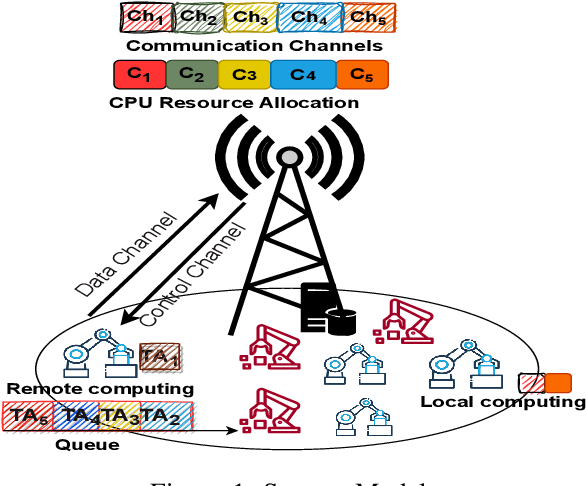
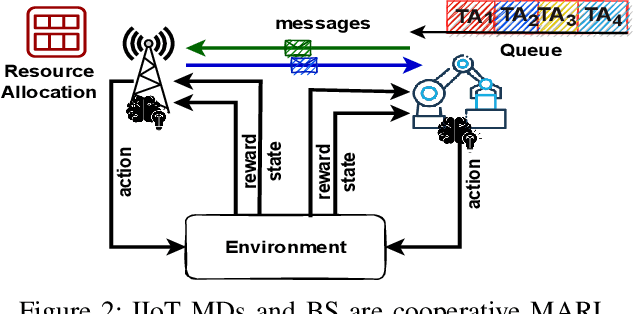
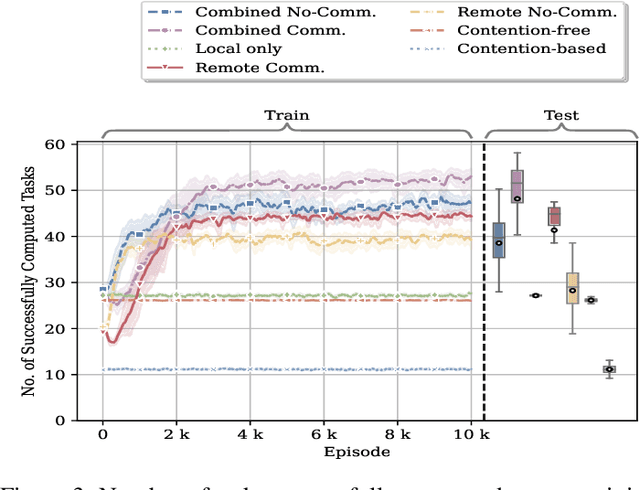
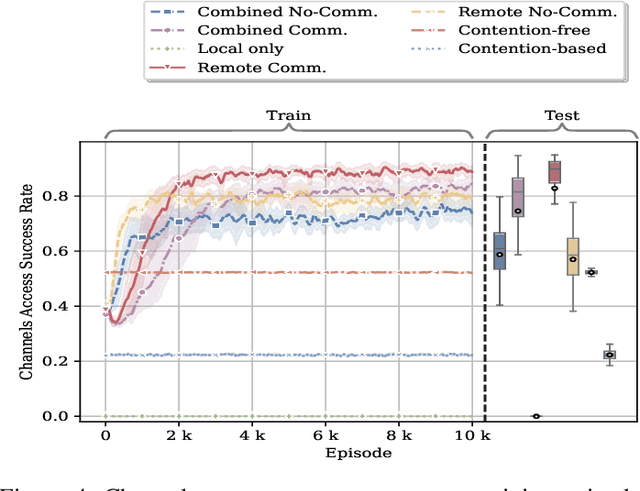
In this paper, we leverage a multi-agent reinforcement learning (MARL) framework to jointly learn a computation offloading decision and multichannel access policy with corresponding signaling. Specifically, the base station and industrial Internet of Things mobile devices are reinforcement learning agents that need to cooperate to execute their computation tasks within a deadline constraint. We adopt an emergent communication protocol learning framework to solve this problem. The numerical results illustrate the effectiveness of emergent communication in improving the channel access success rate and the number of successfully computed tasks compared to contention-based, contention-free, and no-communication approaches. Moreover, the proposed task offloading policy outperforms remote and local computation baselines.
Scalable Joint Learning of Wireless Multiple-Access Policies and their Signaling
Jun 08, 2022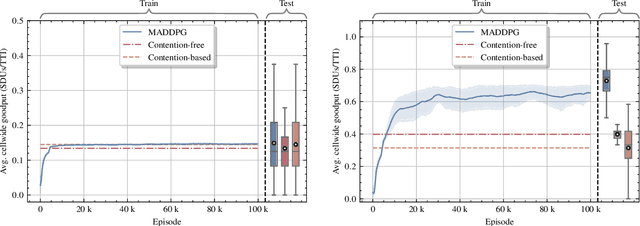
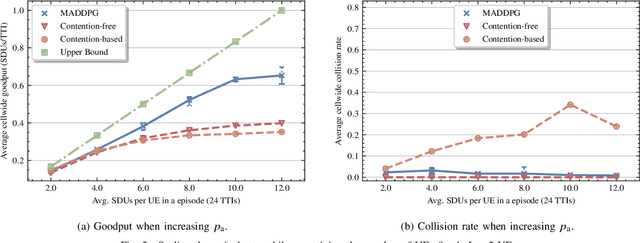
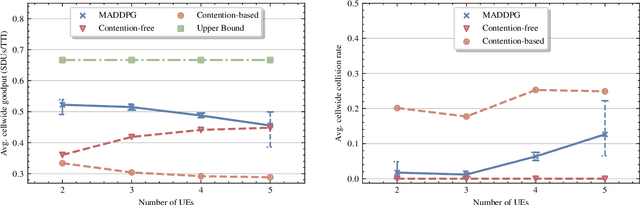
In this paper, we apply an multi-agent reinforcement learning (MARL) framework allowing the base station (BS) and the user equipments (UEs) to jointly learn a channel access policy and its signaling in a wireless multiple access scenario. In this framework, the BS and UEs are reinforcement learning (RL) agents that need to cooperate in order to deliver data. The comparison with a contention-free and a contention-based baselines shows that our framework achieves a superior performance in terms of goodput even in high traffic situations while maintaining a low collision rate. The scalability of the proposed method is studied, since it is a major problem in MARL and this paper provides the first results in order to address it.
The Emergence of Wireless MAC Protocols with Multi-Agent Reinforcement Learning
Aug 17, 2021



In this paper, we propose a new framework, exploiting the multi-agent deep deterministic policy gradient (MADDPG) algorithm, to enable a base station (BS) and user equipment (UE) to come up with a medium access control (MAC) protocol in a multiple access scenario. In this framework, the BS and UEs are reinforcement learning (RL) agents that need to learn to cooperate in order to deliver data. The network nodes can exchange control messages to collaborate and deliver data across the network, but without any prior agreement on the meaning of the control messages. In such a framework, the agents have to learn not only the channel access policy, but also the signaling policy. The collaboration between agents is shown to be important, by comparing the proposed algorithm to ablated versions where either the communication between agents or the central critic is removed. The comparison with a contention-free baseline shows that our framework achieves a superior performance in terms of goodput and can effectively be used to learn a new protocol.
Adaptive Modulation and Coding based on Reinforcement Learning for 5G Networks
Nov 25, 2019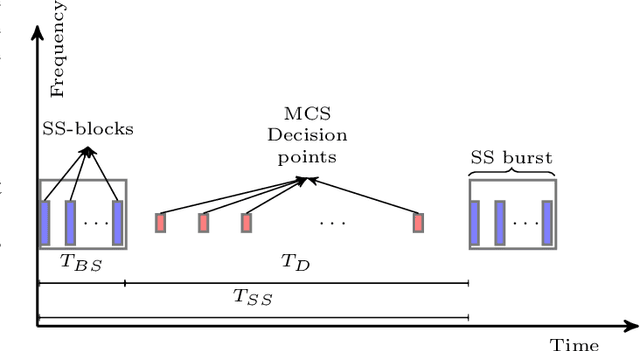
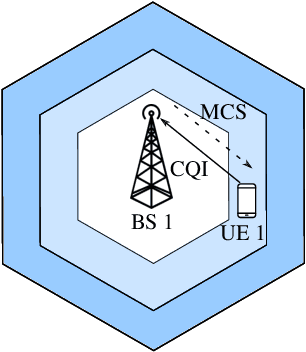
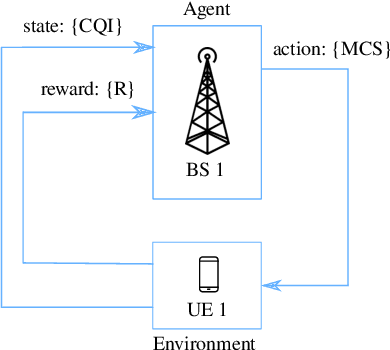
We design a self-exploratory reinforcement learning (RL) framework, based on the Q-learning algorithm, that enables the base station (BS) to choose a suitable modulation and coding scheme (MCS) that maximizes the spectral efficiency while maintaining a low block error rate (BLER). In this framework, the BS chooses the MCS based on the channel quality indicator (CQI) reported by the user equipment (UE). A transmission is made with the chosen MCS and the results of this transmission are converted by the BS into rewards that the BS uses to learn the suitable mapping from CQI to MCS. Comparing with a conventional fixed look-up table and the outer loop link adaptation, the proposed framework achieves superior performance in terms of spectral efficiency and BLER.