Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Joint Learning of Wireless Multiple-Access Policies and their Signaling
Paper and Code
Jun 08, 2022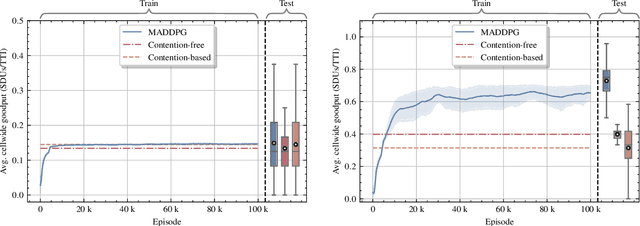
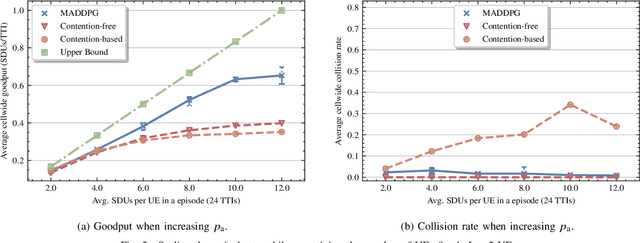
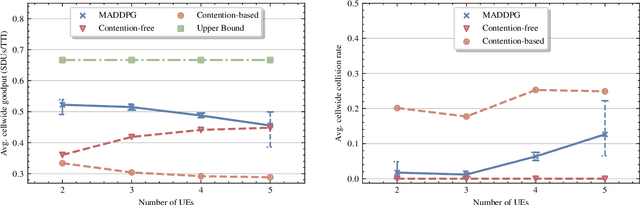
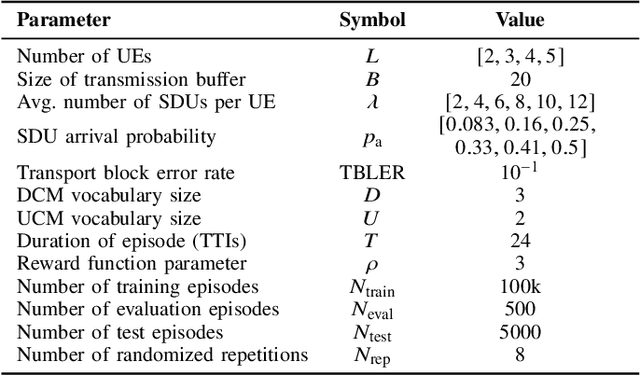
In this paper, we apply an multi-agent reinforcement learning (MARL) framework allowing the base station (BS) and the user equipments (UEs) to jointly learn a channel access policy and its signaling in a wireless multiple access scenario. In this framework, the BS and UEs are reinforcement learning (RL) agents that need to cooperate in order to deliver data. The comparison with a contention-free and a contention-based baselines shows that our framework achieves a superior performance in terms of goodput even in high traffic situations while maintaining a low collision rate. The scalability of the proposed method is studied, since it is a major problem in MARL and this paper provides the first results in order to address it.
* Paper accepted at VTC 2022 Spring Workshops. arXiv admin note:
substantial text overlap with arXiv:2108.07144
View paper on