 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering a Mixture of Gaussians with Unknown Covariance
Oct 04, 2021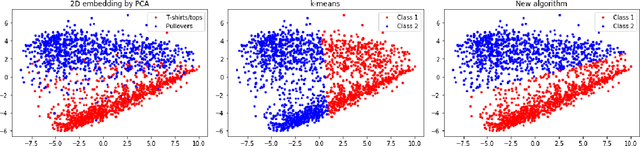

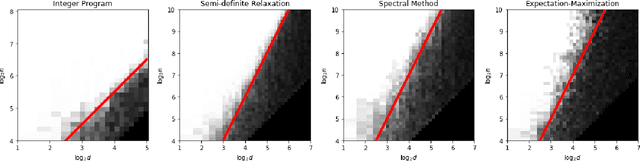
We investigate a clustering problem with data from a mixture of Gaussians that share a common but unknown, and potentially ill-conditioned, covariance matrix. We start by considering Gaussian mixtures with two equally-sized components and derive a Max-Cut integer program based on maximum likelihood estimation. We prove its solutions achieve the optimal misclassification rate when the number of samples grows linearly in the dimension, up to a logarithmic factor. However, solving the Max-cut problem appears to be computationally intractable. To overcome this, we develop an efficient spectral algorithm that attains the optimal rate but requires a quadratic sample size. Although this sample complexity is worse than that of the Max-cut problem, we conjecture that no polynomial-time method can perform better. Furthermore, we gather numerical and theoretical evidence that supports the existence of a statistical-computational gap. Finally, we generalize the Max-Cut program to a $k$-means program that handles multi-component mixtures with possibly unequal weights. It enjoys similar optimality guarantees for mixtures of distributions that satisfy a transportation-cost inequality, encompassing Gaussian and strongly log-concave distributions.
Efficient Clustering for Stretched Mixtures: Landscape and Optimality
Apr 26, 2020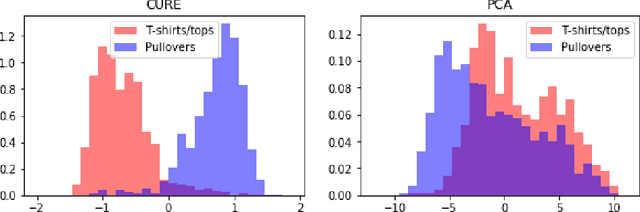
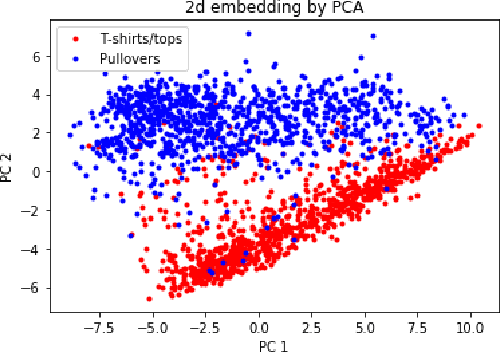
This paper considers a canonical clustering problem where one receives unlabeled samples drawn from a balanced mixture of two elliptical distributions and aims for a classifier to estimate the labels. Many popular methods including PCA and k-means require individual components of the mixture to be somewhat spherical, and perform poorly when they are stretched. To overcome this issue, we propose a non-convex program seeking for an affine transform to turn the data into a one-dimensional point cloud concentrating around -1 and 1, after which clustering becomes easy. Our theoretical contributions are two-fold: (1) we show that the non-convex loss function exhibits desirable landscape properties as long as the sample size exceeds some constant multiple of the dimension, and (2) we leverage this to prove that an efficient first-order algorithm achieves near-optimal statistical precision even without good initialization. We also propose a general methodology for multi-class clustering tasks with flexible choices of feature transforms and loss objectives.