 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Interpolation of Incident Sound Field in Region Including Scattering Objects
Sep 11, 2023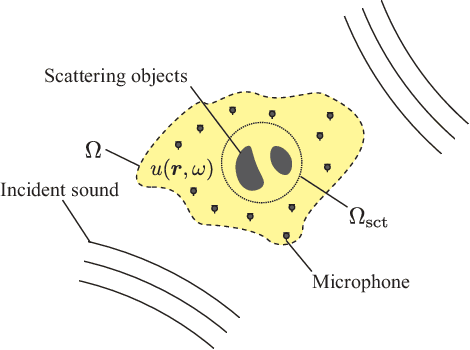
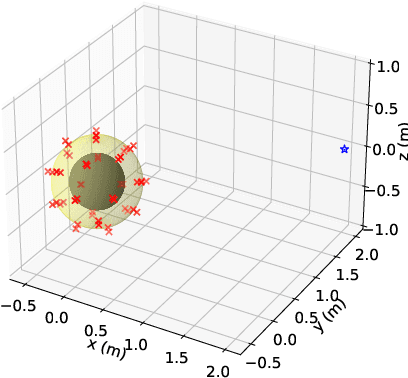
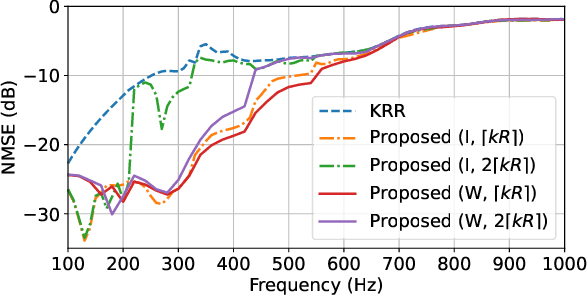
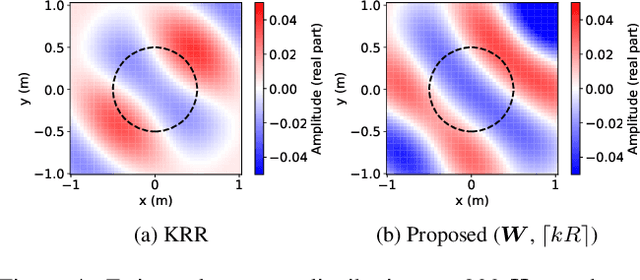
A method for estimating the incident sound field inside a region containing scattering objects is proposed. The sound field estimation method has various applications, such as spatial audio capturing and spatial active noise control; however, most existing methods do not take into account the presence of scatterers within the target estimation region. Although several techniques exist that employ knowledge or measurements of the properties of the scattering objects, it is usually difficult to obtain them precisely in advance, and their properties may change during the estimation process. Our proposed method is based on the kernel ridge regression of the incident field, with a separation from the scattering field represented by a spherical wave function expansion, thus eliminating the need for prior modeling or measurements of the scatterers. Moreover, we introduce a weighting matrix to induce smoothness of the scattering field in the angular direction, which alleviates the effect of the truncation order of the expansion coefficients on the estimation accuracy. Experimental results indicate that the proposed method achieves a higher level of estimation accuracy than the kernel ridge regression without separation.
Neuromuscular Control of the Face-Head-Neck Biomechanical Complex With Learning-Based Expression Transfer From Images and Videos
Nov 12, 2021

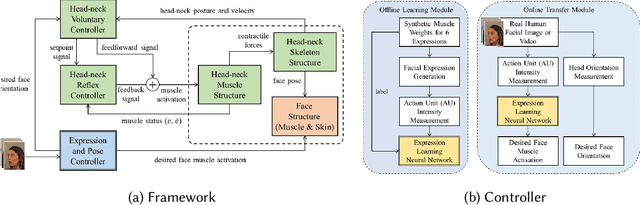

The transfer of facial expressions from people to 3D face models is a classic computer graphics problem. In this paper, we present a novel, learning-based approach to transferring facial expressions and head movements from images and videos to a biomechanical model of the face-head-neck complex. Leveraging the Facial Action Coding System (FACS) as an intermediate representation of the expression space, we train a deep neural network to take in FACS Action Units (AUs) and output suitable facial muscle and jaw activation signals for the musculoskeletal model. Through biomechanical simulation, the activations deform the facial soft tissues, thereby transferring the expression to the model. Our approach has advantages over previous approaches. First, the facial expressions are anatomically consistent as our biomechanical model emulates the relevant anatomy of the face, head, and neck. Second, by training the neural network using data generated from the biomechanical model itself, we eliminate the manual effort of data collection for expression transfer. The success of our approach is demonstrated through experiments involving the transfer onto our face-head-neck model of facial expressions and head poses from a range of facial images and videos.