 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Deep Learning Colon Cancer Detection in Limited Data Access Scenarios
May 22, 2020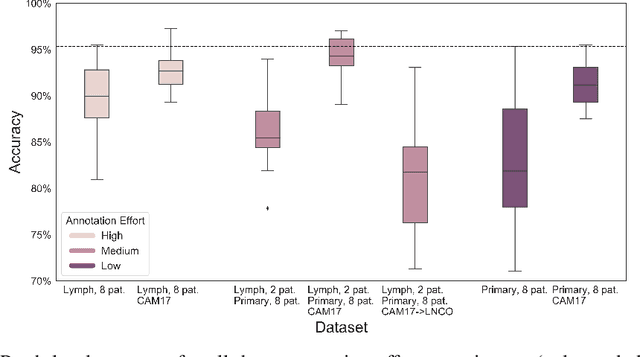
Digitization of histopathology slides has led to several advances, from easy data sharing and collaborations to the development of digital diagnostic tools. Deep learning (DL) methods for classification and detection have shown great potential, but often require large amounts of training data that are hard to collect, and annotate. For many cancer types, the scarceness of data creates barriers for training DL models. One such scenario relates to detecting tumor metastasis in lymph node tissue, where the low ratio of tumor to non-tumor cells makes the diagnostic task hard and time-consuming. DL-based tools can allow faster diagnosis, with potentially increased quality. Unfortunately, due to the sparsity of tumor cells, annotating this type of data demands a high level of effort from pathologists. Using weak annotations from slide-level images have shown great potential, but demand access to a substantial amount of data as well. In this study, we investigate mitigation strategies for limited data access scenarios. Particularly, we address whether it is possible to exploit mutual structure between tissues to develop general techniques, wherein data from one type of cancer in a particular tissue could have diagnostic value for other cancers in other tissues. Our case is exemplified by a DL model for metastatic colon cancer detection in lymph nodes. Could such a model be trained with little or even no lymph node data? As alternative data sources, we investigate 1) tumor cells taken from the primary colon tumor tissue, and 2) cancer data from a different organ (breast), either as is or transformed to the target domain (colon) using Cycle-GANs. We show that the suggested approaches make it possible to detect cancer metastasis with no or very little lymph node data, opening up for the possibility that existing, annotated histopathology data could generalize to other domains.
Designing for the Long Tail of Machine Learning
Jan 21, 2020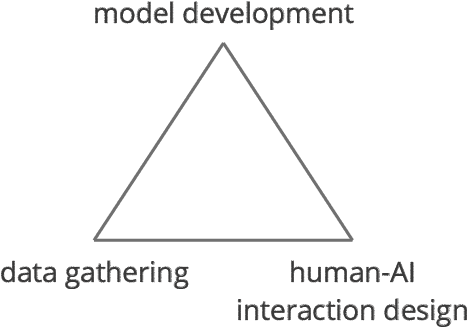
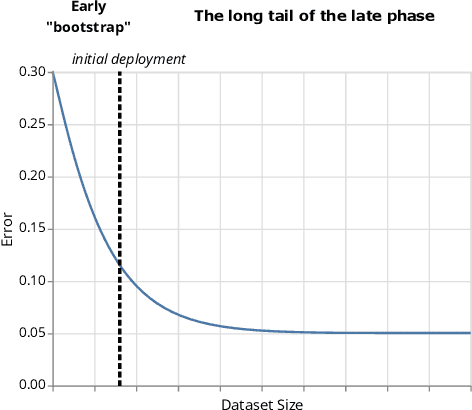
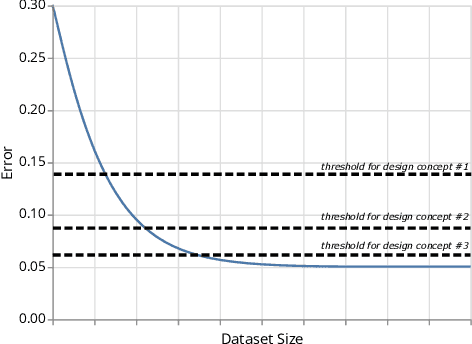
Recent technical advances has made machine learning (ML) a promising component to include in end user facing systems. However, user experience (UX) practitioners face challenges in relating ML to existing user-centered design processes and how to navigate the possibilities and constraints of this design space. Drawing on our own experience, we characterize designing within this space as navigating trade-offs between data gathering, model development and designing valuable interactions for a given model performance. We suggest that the theoretical description of how machine learning performance scales with training data can guide designers in these trade-offs as well as having implications for prototyping. We exemplify the learning curve's usage by arguing that a useful pattern is to design an initial system in a bootstrap phase that aims to exploit the training effect of data collected at increasing orders of magnitude.