 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-State Controllers for (Hidden-Model) POMDPs using Deep Reinforcement Learning
Feb 09, 2026Solving partially observable Markov decision processes (POMDPs) requires computing policies under imperfect state information. Despite recent advances, the scalability of existing POMDP solvers remains limited. Moreover, many settings require a policy that is robust across multiple POMDPs, further aggravating the scalability issue. We propose the Lexpop framework for POMDP solving. Lexpop (1) employs deep reinforcement learning to train a neural policy, represented by a recurrent neural network, and (2) constructs a finite-state controller mimicking the neural policy through efficient extraction methods. Crucially, unlike neural policies, such controllers can be formally evaluated, providing performance guarantees. We extend Lexpop to compute robust policies for hidden-model POMDPs (HM-POMDPs), which describe finite sets of POMDPs. We associate every extracted controller with its worst-case POMDP. Using a set of such POMDPs, we iteratively train a robust neural policy and consequently extract a robust controller. Our experiments show that on problems with large state spaces, Lexpop outperforms state-of-the-art solvers for POMDPs as well as HM-POMDPs.
Bidding Games on Markov Decision Processes with Quantitative Reachability Objectives
Dec 27, 2024Graph games are fundamental in strategic reasoning of multi-agent systems and their environments. We study a new family of graph games which combine stochastic environmental uncertainties and auction-based interactions among the agents, formalized as bidding games on (finite) Markov decision processes (MDP). Normally, on MDPs, a single decision-maker chooses a sequence of actions, producing a probability distribution over infinite paths. In bidding games on MDPs, two players -- called the reachability and safety players -- bid for the privilege of choosing the next action at each step. The reachability player's goal is to maximize the probability of reaching a target vertex, whereas the safety player's goal is to minimize it. These games generalize traditional bidding games on graphs, and the existing analysis techniques do not extend. For instance, the central property of traditional bidding games is the existence of a threshold budget, which is a necessary and sufficient budget to guarantee winning for the reachability player. For MDPs, the threshold becomes a relation between the budgets and probabilities of reaching the target. We devise value-iteration algorithms that approximate thresholds and optimal policies for general MDPs, and compute the exact solutions for acyclic MDPs, and show that finding thresholds is at least as hard as solving simple-stochastic games.
Threshold UCT: Cost-Constrained Monte Carlo Tree Search with Pareto Curves
Dec 18, 2024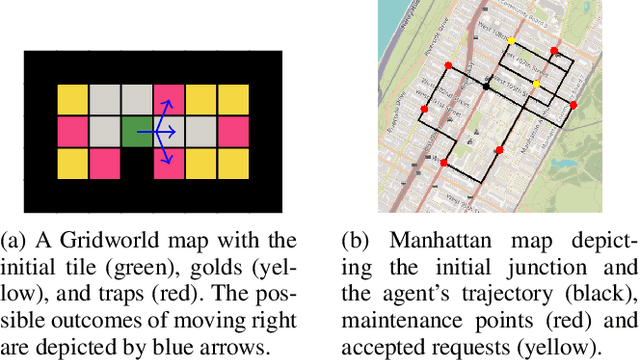

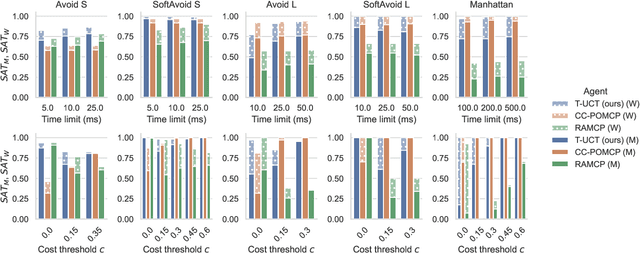
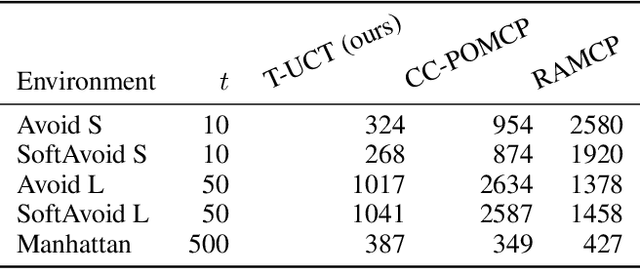
Constrained Markov decision processes (CMDPs), in which the agent optimizes expected payoffs while keeping the expected cost below a given threshold, are the leading framework for safe sequential decision making under stochastic uncertainty. Among algorithms for planning and learning in CMDPs, methods based on Monte Carlo tree search (MCTS) have particular importance due to their efficiency and extendibility to more complex frameworks (such as partially observable settings and games). However, current MCTS-based methods for CMDPs either struggle with finding safe (i.e., constraint-satisfying) policies, or are too conservative and do not find valuable policies. We introduce Threshold UCT (T-UCT), an online MCTS-based algorithm for CMDP planning. Unlike previous MCTS-based CMDP planners, T-UCT explicitly estimates Pareto curves of cost-utility trade-offs throughout the search tree, using these together with a novel action selection and threshold update rules to seek safe and valuable policies. Our experiments demonstrate that our approach significantly outperforms state-of-the-art methods from the literature.