 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Ensemble Size Adjustment for Memory Constrained Mondrian Forest
Oct 11, 2022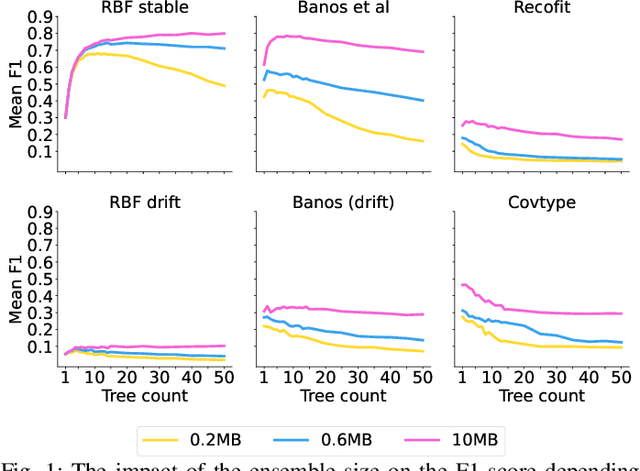
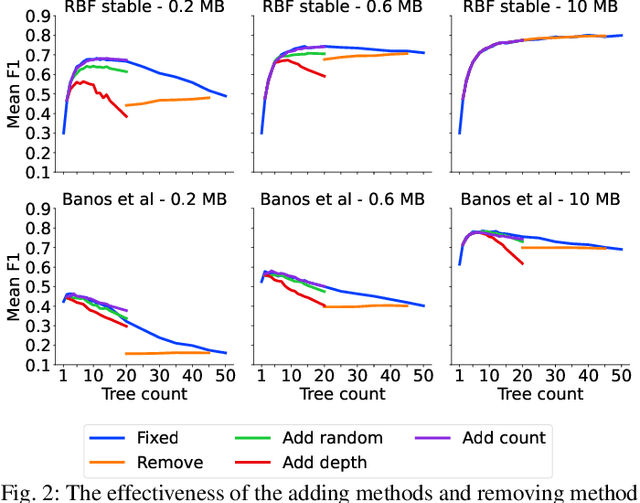
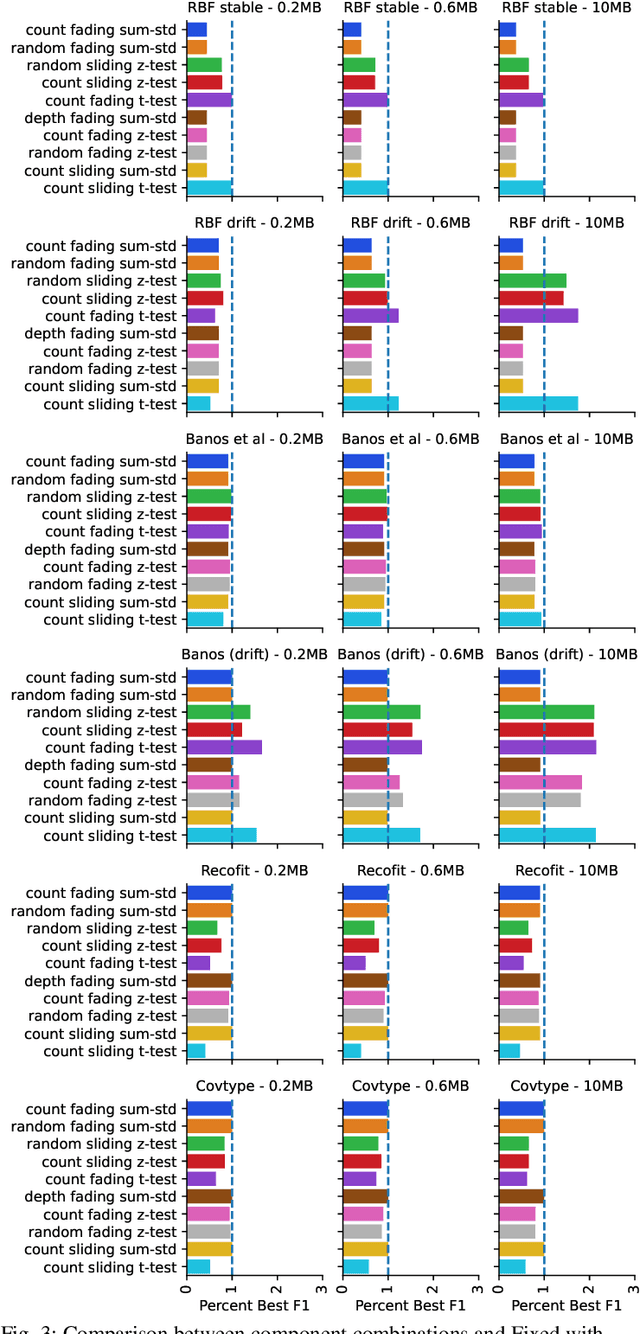
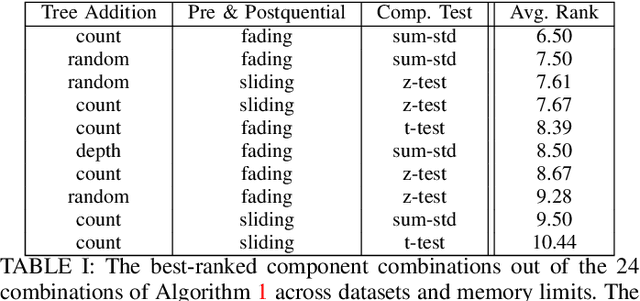
Supervised learning algorithms generally assume the availability of enough memory to store data models during the training and test phases. However, this assumption is unrealistic when data comes in the form of infinite data streams, or when learning algorithms are deployed on devices with reduced amounts of memory. Such memory constraints impact the model behavior and assumptions. In this paper, we show that under memory constraints, increasing the size of a tree-based ensemble classifier can worsen its performance. In particular, we experimentally show the existence of an optimal ensemble size for a memory-bounded Mondrian forest on data streams and we design an algorithm to guide the forest toward that optimal number by using an estimation of overfitting. We tested different variations for this algorithm on a variety of real and simulated datasets, and we conclude that our method can achieve up to 95% of the performance of an optimally-sized Mondrian forest for stable datasets, and can even outperform it for datasets with concept drifts. All our methods are implemented in the OrpailleCC open-source library and are ready to be used on embedded systems and connected objects.
Mondrian Forest for Data Stream Classification Under Memory Constraints
May 12, 2022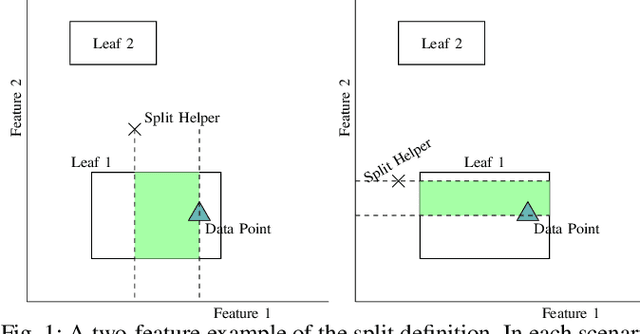
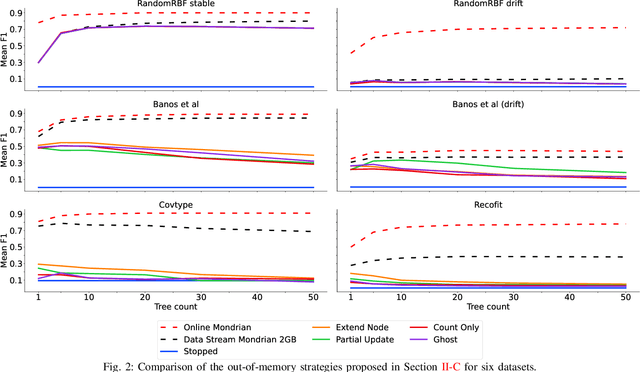
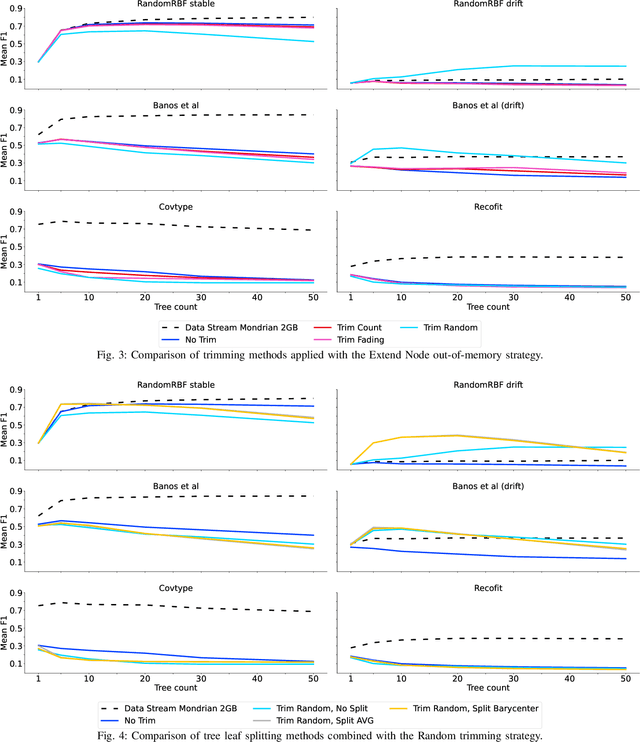

Supervised learning algorithms generally assume the availability of enough memory to store their data model during the training and test phases. However, in the Internet of Things, this assumption is unrealistic when data comes in the form of infinite data streams, or when learning algorithms are deployed on devices with reduced amounts of memory. In this paper, we adapt the online Mondrian forest classification algorithm to work with memory constraints on data streams. In particular, we design five out-of-memory strategies to update Mondrian trees with new data points when the memory limit is reached. Moreover, we design trimming mechanisms to make Mondrian trees more robust to concept drifts under memory constraints. We evaluate our algorithms on a variety of real and simulated datasets, and we conclude with recommendations on their use in different situations: the Extend Node strategy appears as the best out-of-memory strategy in all configurations, whereas different trimming mechanisms should be adopted depending on whether a concept drift is expected. All our methods are implemented in the OrpailleCC open-source library and are ready to be used on embedded systems and connected objects.
Reducing numerical precision preserves classification accuracy in Mondrian Forests
Jun 28, 2021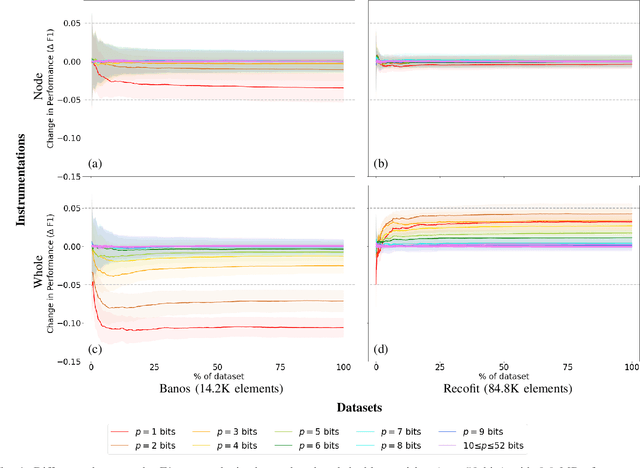
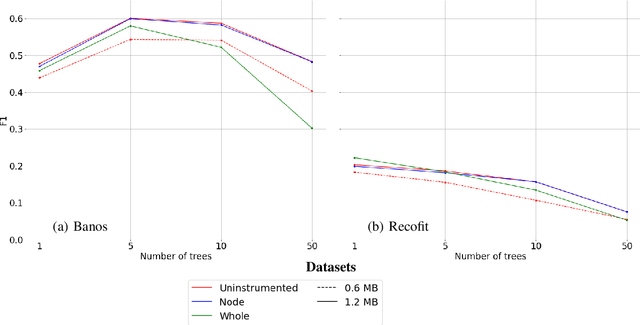

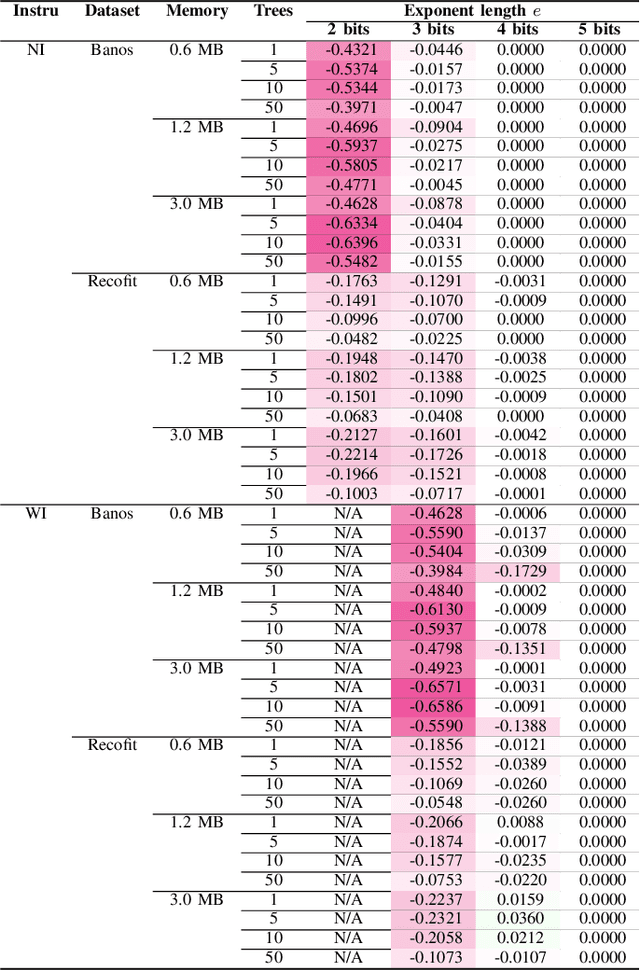
Mondrian Forests are a powerful data stream classification method, but their large memory footprint makes them ill-suited for low-resource platforms such as connected objects. We explored using reduced-precision floating-point representations to lower memory consumption and evaluated its effect on classification performance. We applied the Mondrian Forest implementation provided by OrpailleCC, a C++ collection of data stream algorithms, to two canonical datasets in human activity recognition: Recofit and Banos \emph{et al}. Results show that the precision of floating-point values used by tree nodes can be reduced from 64 bits to 8 bits with no significant difference in F1 score. In some cases, reduced precision was shown to improve classification performance, presumably due to its regularization effect. We conclude that numerical precision is a relevant hyperparameter in the Mondrian Forest, and that commonly-used double precision values may not be necessary for optimal performance. Future work will evaluate the generalizability of these findings to other data stream classifiers.
A benchmark of data stream classification for human activity recognition on connected objects
Aug 27, 2020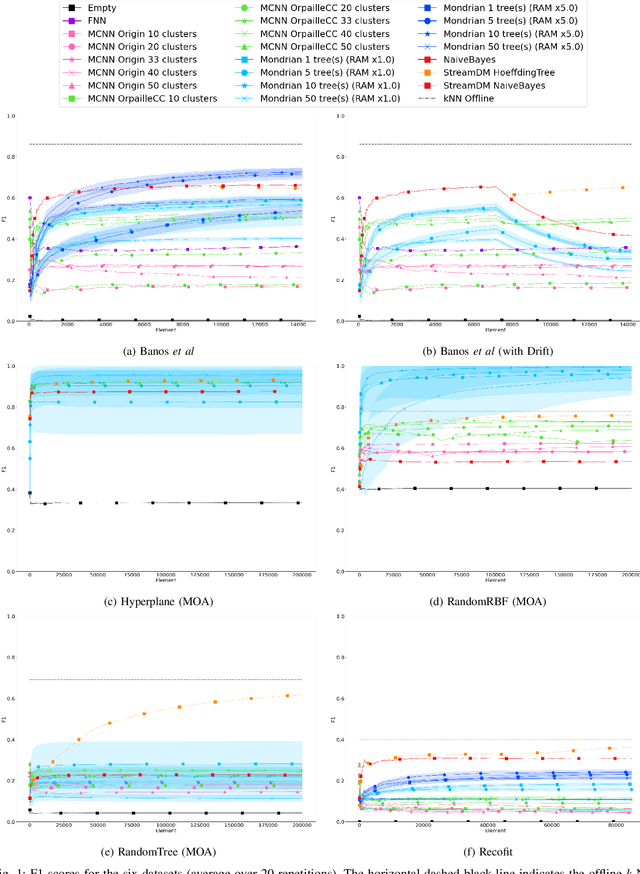
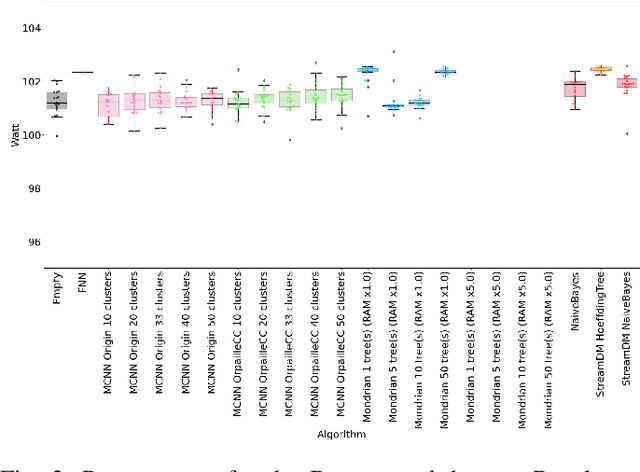
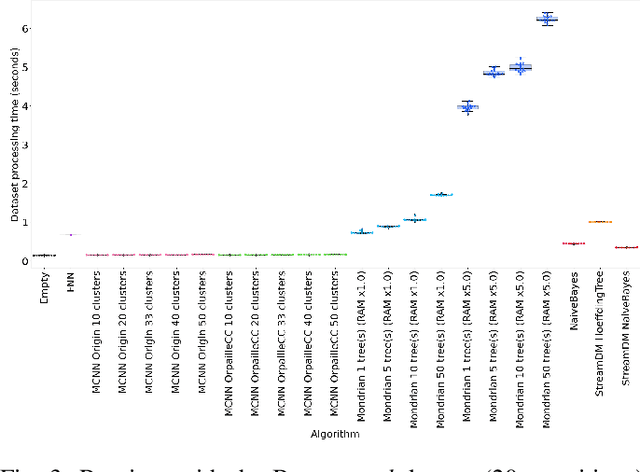
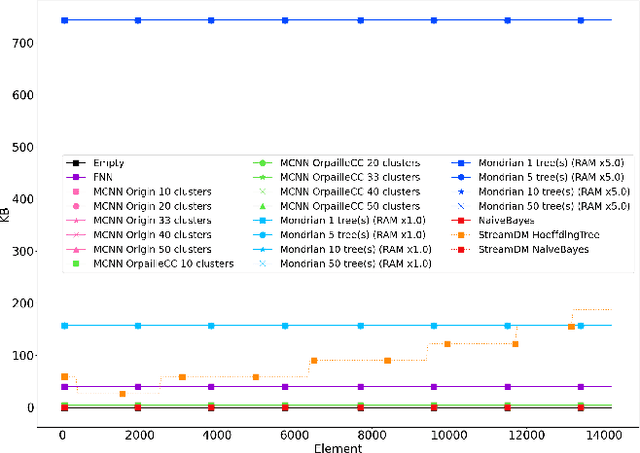
This paper evaluates data stream classifiers from the perspective of connected devices, focusing on the use case of HAR. We measure both classification performance and resource consumption (runtime, memory, and power) of five usual stream classification algorithms, implemented in a consistent library, and applied to two real human activity datasets and to three synthetic datasets. Regarding classification performance, results show an overall superiority of the HT, the MF, and the NB classifiers over the FNN and the Micro Cluster Nearest Neighbor (MCNN) classifiers on 4 datasets out of 6, including the real ones. In addition, the HT, and to some extent MCNN, are the only classifiers that can recover from a concept drift. Overall, the three leading classifiers still perform substantially lower than an offline classifier on the real datasets. Regarding resource consumption, the HT and the MF are the most memory intensive and have the longest runtime, however, no difference in power consumption is found between classifiers. We conclude that stream learning for HAR on connected objects is challenged by two factors which could lead to interesting future work: a high memory consumption and low F1 scores overall.