 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Ensemble Size Adjustment for Memory Constrained Mondrian Forest
Paper and Code
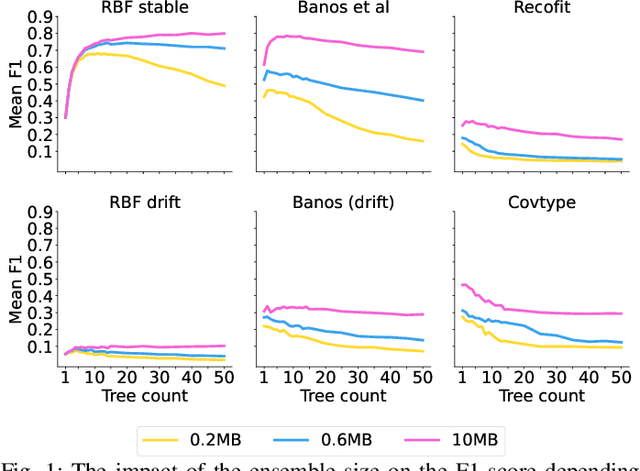
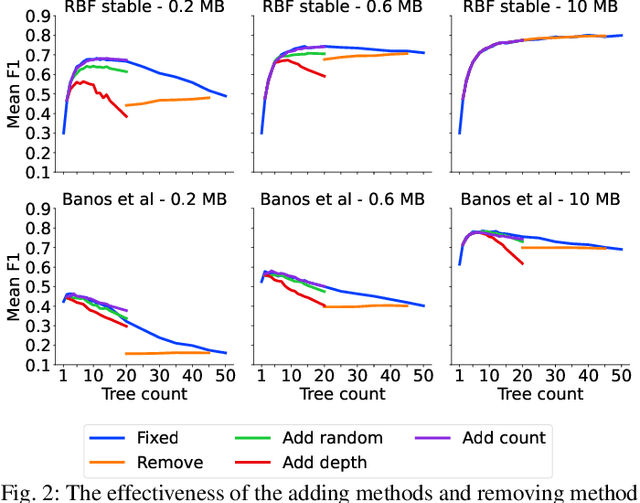
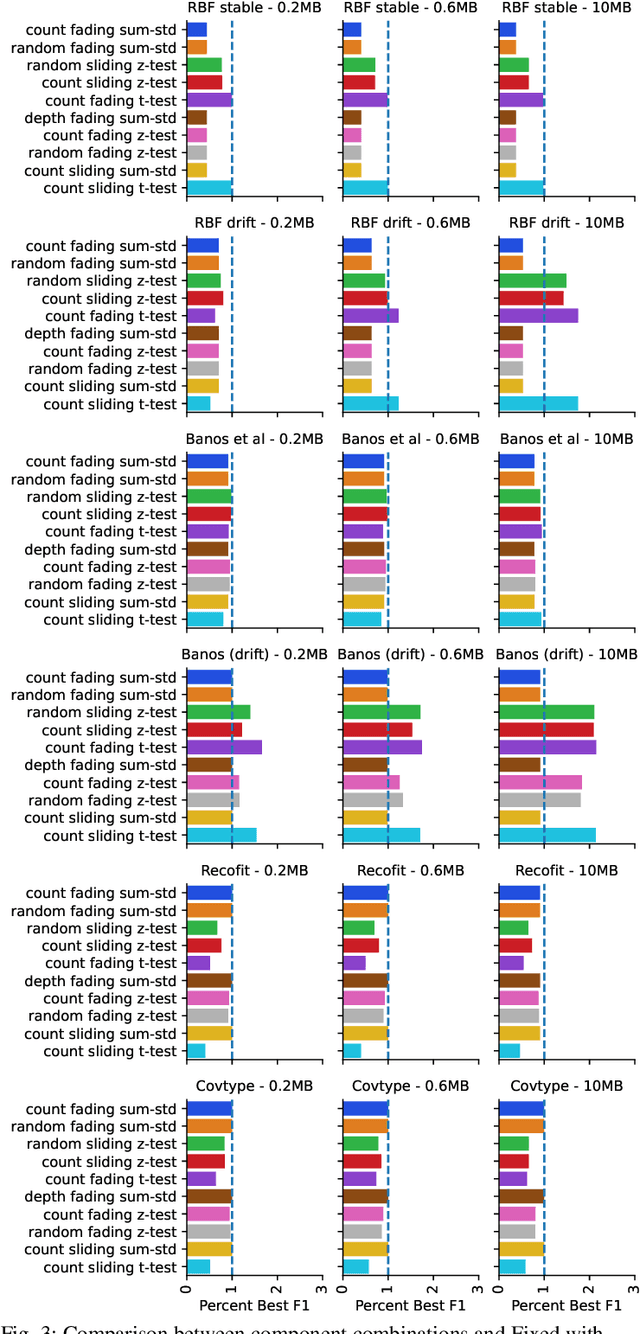
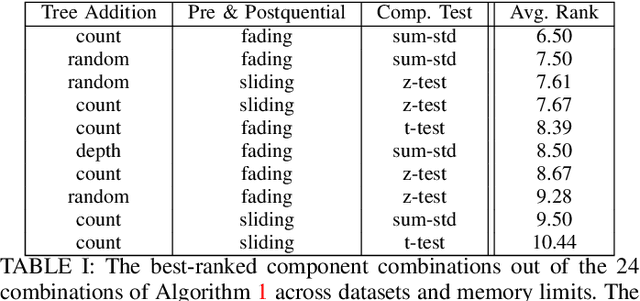
Supervised learning algorithms generally assume the availability of enough memory to store data models during the training and test phases. However, this assumption is unrealistic when data comes in the form of infinite data streams, or when learning algorithms are deployed on devices with reduced amounts of memory. Such memory constraints impact the model behavior and assumptions. In this paper, we show that under memory constraints, increasing the size of a tree-based ensemble classifier can worsen its performance. In particular, we experimentally show the existence of an optimal ensemble size for a memory-bounded Mondrian forest on data streams and we design an algorithm to guide the forest toward that optimal number by using an estimation of overfitting. We tested different variations for this algorithm on a variety of real and simulated datasets, and we conclude that our method can achieve up to 95% of the performance of an optimally-sized Mondrian forest for stable datasets, and can even outperform it for datasets with concept drifts. All our methods are implemented in the OrpailleCC open-source library and are ready to be used on embedded systems and connected objects.