 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ADUULM-360 Dataset -- A Multi-Modal Dataset for Depth Estimation in Adverse Weather
Nov 18, 2024Depth estimation is an essential task toward full scene understanding since it allows the projection of rich semantic information captured by cameras into 3D space. While the field has gained much attention recently, datasets for depth estimation lack scene diversity or sensor modalities. This work presents the ADUULM-360 dataset, a novel multi-modal dataset for depth estimation. The ADUULM-360 dataset covers all established autonomous driving sensor modalities, cameras, lidars, and radars. It covers a frontal-facing stereo setup, six surround cameras covering the full 360-degree, two high-resolution long-range lidar sensors, and five long-range radar sensors. It is also the first depth estimation dataset that contains diverse scenes in good and adverse weather conditions. We conduct extensive experiments using state-of-the-art self-supervised depth estimation methods under different training tasks, such as monocular training, stereo training, and full surround training. Discussing these results, we demonstrate common limitations of state-of-the-art methods, especially in adverse weather conditions, which hopefully will inspire future research in this area. Our dataset, development kit, and trained baselines are available at https://github.com/uulm-mrm/aduulm_360_dataset.
MGNiceNet: Unified Monocular Geometric Scene Understanding
Nov 18, 2024Monocular geometric scene understanding combines panoptic segmentation and self-supervised depth estimation, focusing on real-time application in autonomous vehicles. We introduce MGNiceNet, a unified approach that uses a linked kernel formulation for panoptic segmentation and self-supervised depth estimation. MGNiceNet is based on the state-of-the-art real-time panoptic segmentation method RT-K-Net and extends the architecture to cover both panoptic segmentation and self-supervised monocular depth estimation. To this end, we introduce a tightly coupled self-supervised depth estimation predictor that explicitly uses information from the panoptic path for depth prediction. Furthermore, we introduce a panoptic-guided motion masking method to improve depth estimation without relying on video panoptic segmentation annotations. We evaluate our method on two popular autonomous driving datasets, Cityscapes and KITTI. Our model shows state-of-the-art results compared to other real-time methods and closes the gap to computationally more demanding methods. Source code and trained models are available at https://github.com/markusschoen/MGNiceNet.
RT-K-Net: Revisiting K-Net for Real-Time Panoptic Segmentation
May 02, 2023Panoptic segmentation is one of the most challenging scene parsing tasks, combining the tasks of semantic segmentation and instance segmentation. While much progress has been made, few works focus on the real-time application of panoptic segmentation methods. In this paper, we revisit the recently introduced K-Net architecture. We propose vital changes to the architecture, training, and inference procedure, which massively decrease latency and improve performance. Our resulting RT-K-Net sets a new state-of-the-art performance for real-time panoptic segmentation methods on the Cityscapes dataset and shows promising results on the challenging Mapillary Vistas dataset. On Cityscapes, RT-K-Net reaches 60.2 % PQ with an average inference time of 32 ms for full resolution 1024x2048 pixel images on a single Titan RTX GPU. On Mapillary Vistas, RT-K-Net reaches 33.2 % PQ with an average inference time of 69 ms. Source code is available at https://github.com/markusschoen/RT-K-Net.
MGNet: Monocular Geometric Scene Understanding for Autonomous Driving
Jun 27, 2022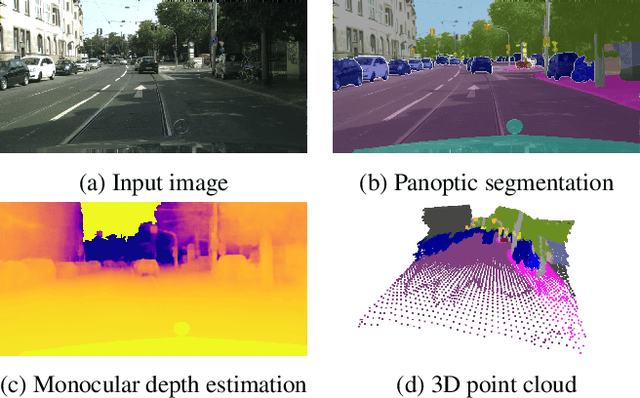

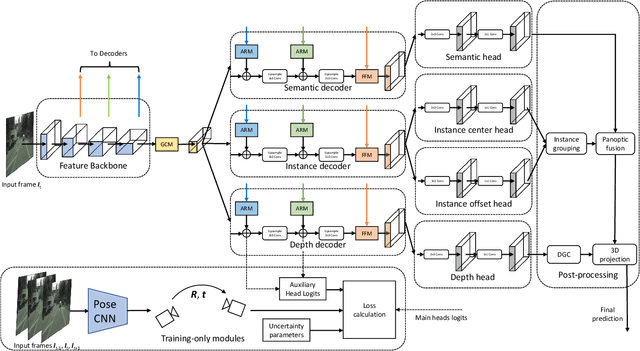
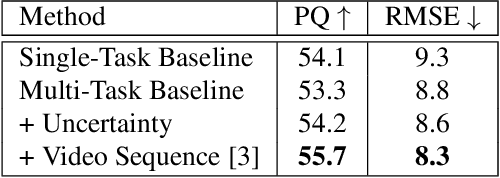
We introduce MGNet, a multi-task framework for monocular geometric scene understanding. We define monocular geometric scene understanding as the combination of two known tasks: Panoptic segmentation and self-supervised monocular depth estimation. Panoptic segmentation captures the full scene not only semantically, but also on an instance basis. Self-supervised monocular depth estimation uses geometric constraints derived from the camera measurement model in order to measure depth from monocular video sequences only. To the best of our knowledge, we are the first to propose the combination of these two tasks in one single model. Our model is designed with focus on low latency to provide fast inference in real-time on a single consumer-grade GPU. During deployment, our model produces dense 3D point clouds with instance aware semantic labels from single high-resolution camera images. We evaluate our model on two popular autonomous driving benchmarks, i.e., Cityscapes and KITTI, and show competitive performance among other real-time capable methods. Source code is available at https://github.com/markusschoen/MGNet.