 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Machine Learning Models and Datasets for the Multi-label Classification of Textual Hate Speech in English
Apr 11, 2025

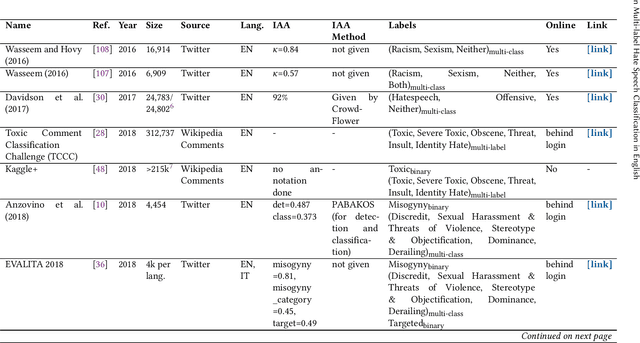

The dissemination of online hate speech can have serious negative consequences for individuals, online communities, and entire societies. This and the large volume of hateful online content prompted both practitioners', i.e., in content moderation or law enforcement, and researchers' interest in machine learning models to automatically classify instances of hate speech. Whereas most scientific works address hate speech classification as a binary task, practice often requires a differentiation into sub-types, e.g., according to target, severity, or legality, which may overlap for individual content. Hence, researchers created datasets and machine learning models that approach hate speech classification in textual data as a multi-label problem. This work presents the first systematic and comprehensive survey of scientific literature on this emerging research landscape in English (N=46). We contribute with a concise overview of 28 datasets suited for training multi-label classification models that reveals significant heterogeneity regarding label-set, size, meta-concept, annotation process, and inter-annotator agreement. Our analysis of 24 publications proposing suitable classification models further establishes inconsistency in evaluation and a preference for architectures based on Bidirectional Encoder Representation from Transformers (BERT) and Recurrent Neural Networks (RNNs). We identify imbalanced training data, reliance on crowdsourcing platforms, small and sparse datasets, and missing methodological alignment as critical open issues and formulate ten recommendations for research.
ActiveLLM: Large Language Model-based Active Learning for Textual Few-Shot Scenarios
May 17, 2024Active learning is designed to minimize annotation efforts by prioritizing instances that most enhance learning. However, many active learning strategies struggle with a 'cold start' problem, needing substantial initial data to be effective. This limitation often reduces their utility for pre-trained models, which already perform well in few-shot scenarios. To address this, we introduce ActiveLLM, a novel active learning approach that leverages large language models such as GPT-4, Llama 3, and Mistral Large for selecting instances. We demonstrate that ActiveLLM significantly enhances the classification performance of BERT classifiers in few-shot scenarios, outperforming both traditional active learning methods and the few-shot learning method SetFit. Additionally, ActiveLLM can be extended to non-few-shot scenarios, allowing for iterative selections. In this way, ActiveLLM can even help other active learning strategies to overcome their cold start problem. Our results suggest that ActiveLLM offers a promising solution for improving model performance across various learning setups.
ThreatCrawl: A BERT-based Focused Crawler for the Cybersecurity Domain
Apr 26, 2023Publicly available information contains valuable information for Cyber Threat Intelligence (CTI). This can be used to prevent attacks that have already taken place on other systems. Ideally, only the initial attack succeeds and all subsequent ones are detected and stopped. But while there are different standards to exchange this information, a lot of it is shared in articles or blog posts in non-standardized ways. Manually scanning through multiple online portals and news pages to discover new threats and extracting them is a time-consuming task. To automize parts of this scanning process, multiple papers propose extractors that use Natural Language Processing (NLP) to extract Indicators of Compromise (IOCs) from documents. However, while this already solves the problem of extracting the information out of documents, the search for these documents is rarely considered. In this paper, a new focused crawler is proposed called ThreatCrawl, which uses Bidirectional Encoder Representations from Transformers (BERT)-based models to classify documents and adapt its crawling path dynamically. While ThreatCrawl has difficulties to classify the specific type of Open Source Intelligence (OSINT) named in texts, e.g., IOC content, it can successfully find relevant documents and modify its path accordingly. It yields harvest rates of up to 52%, which are, to the best of our knowledge, better than the current state of the art.
CySecBERT: A Domain-Adapted Language Model for the Cybersecurity Domain
Dec 06, 2022



The field of cybersecurity is evolving fast. Experts need to be informed about past, current and - in the best case - upcoming threats, because attacks are becoming more advanced, targets bigger and systems more complex. As this cannot be addressed manually, cybersecurity experts need to rely on machine learning techniques. In the texutual domain, pre-trained language models like BERT have shown to be helpful, by providing a good baseline for further fine-tuning. However, due to the domain-knowledge and many technical terms in cybersecurity general language models might miss the gist of textual information, hence doing more harm than good. For this reason, we create a high-quality dataset and present a language model specifically tailored to the cybersecurity domain, which can serve as a basic building block for cybersecurity systems that deal with natural language. The model is compared with other models based on 15 different domain-dependent extrinsic and intrinsic tasks as well as general tasks from the SuperGLUE benchmark. On the one hand, the results of the intrinsic tasks show that our model improves the internal representation space of words compared to the other models. On the other hand, the extrinsic, domain-dependent tasks, consisting of sequence tagging and classification, show that the model is best in specific application scenarios, in contrast to the others. Furthermore, we show that our approach against catastrophic forgetting works, as the model is able to retrieve the previously trained domain-independent knowledge. The used dataset and trained model are made publicly available
Multi-Level Fine-Tuning, Data Augmentation, and Few-Shot Learning for Specialized Cyber Threat Intelligence
Jul 22, 2022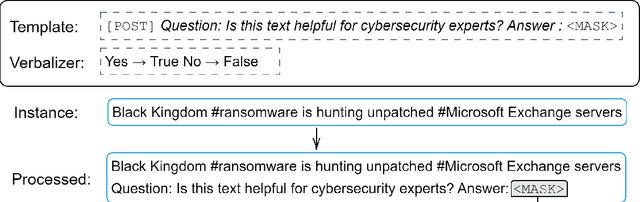
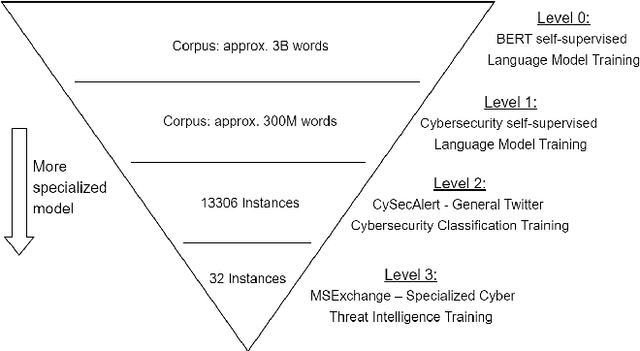
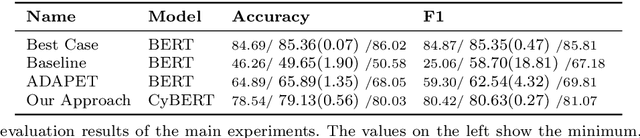
Gathering cyber threat intelligence from open sources is becoming increasingly important for maintaining and achieving a high level of security as systems become larger and more complex. However, these open sources are often subject to information overload. It is therefore useful to apply machine learning models that condense the amount of information to what is necessary. Yet, previous studies and applications have shown that existing classifiers are not able to extract specific information about emerging cybersecurity events due to their low generalization ability. Therefore, we propose a system to overcome this problem by training a new classifier for each new incident. Since this requires a lot of labelled data using standard training methods, we combine three different low-data regime techniques - transfer learning, data augmentation, and few-shot learning - to train a high-quality classifier from very few labelled instances. We evaluated our approach using a novel dataset derived from the Microsoft Exchange Server data breach of 2021 which was labelled by three experts. Our findings reveal an increase in F1 score of more than 21 points compared to standard training methods and more than 18 points compared to a state-of-the-art method in few-shot learning. Furthermore, the classifier trained with this method and 32 instances is only less than 5 F1 score points worse than a classifier trained with 1800 instances.
A Survey on Data Augmentation for Text Classification
Jul 14, 2021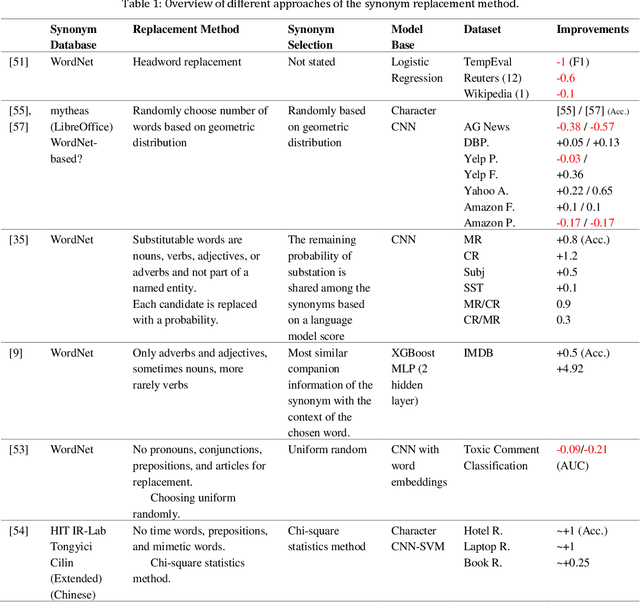
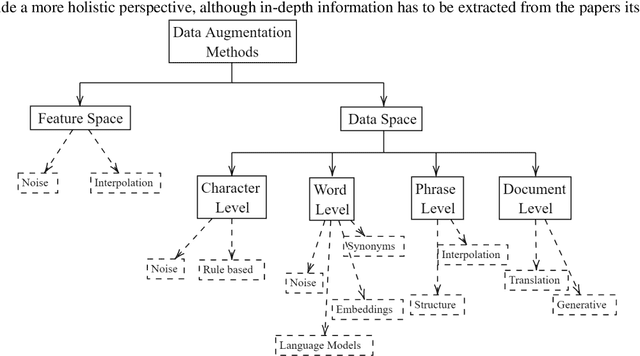
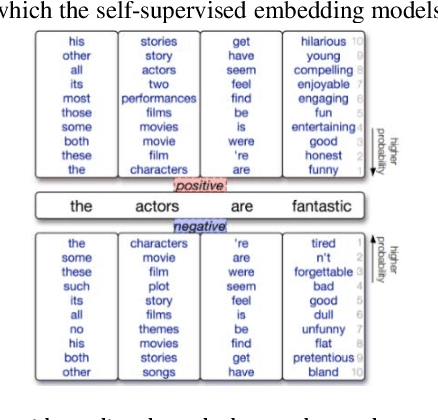
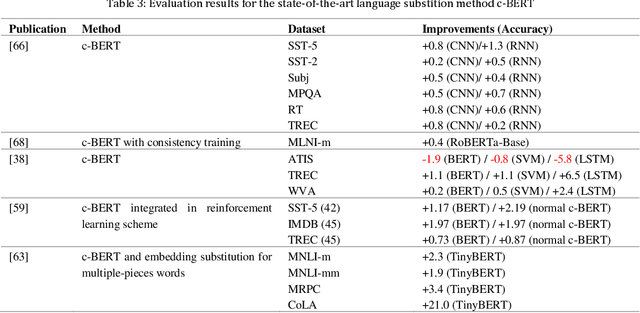
Data augmentation, the artificial creation of training data for machine learning by transformations, is a widely studied research field across machine learning disciplines. While it is useful for increasing the generalization capabilities of a model, it can also address many other challenges and problems, from overcoming a limited amount of training data over regularizing the objective to limiting the amount data used to protect privacy. Based on a precise description of the goals and applications of data augmentation (C1) and a taxonomy for existing works (C2), this survey is concerned with data augmentation methods for textual classification and aims to achieve a concise and comprehensive overview for researchers and practitioners (C3). Derived from the taxonomy, we divided more than 100 methods into 12 different groupings and provide state-of-the-art references expounding which methods are highly promising (C4). Finally, research perspectives that may constitute a building block for future work are given (C5).
Data Augmentation in Natural Language Processing: A Novel Text Generation Approach for Long and Short Text Classifiers
Mar 26, 2021
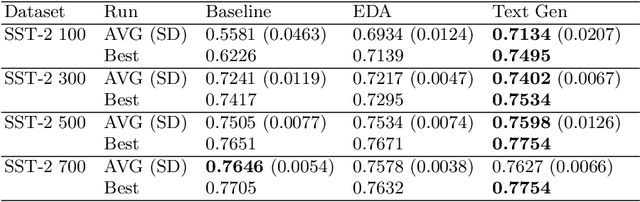

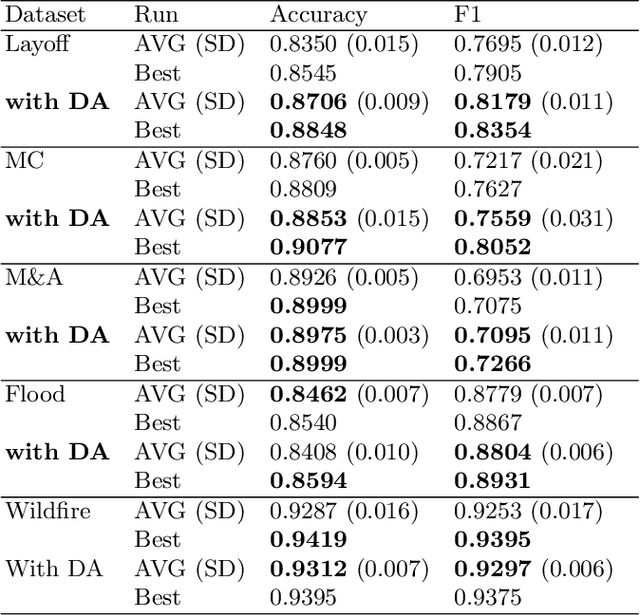
In many cases of machine learning, research suggests that the development of training data might have a higher relevance than the choice and modelling of classifiers themselves. Thus, data augmentation methods have been developed to improve classifiers by artificially created training data. In NLP, there is the challenge of establishing universal rules for text transformations which provide new linguistic patterns. In this paper, we present and evaluate a text generation method suitable to increase the performance of classifiers for long and short texts. We achieved promising improvements when evaluating short as well as long text tasks with the enhancement by our text generation method. In a simulated low data regime additive accuracy gains of up to 15.53% are achieved. As the current track of these constructed regimes is not universally applicable, we also show major improvements in several real world low data tasks (up to +4.84 F1 score). Since we are evaluating the method from many perspectives, we also observe situations where the method might not be suitable. We discuss implications and patterns for the successful application of our approach on different types of datasets.