 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThreatCrawl: A BERT-based Focused Crawler for the Cybersecurity Domain
Apr 26, 2023Publicly available information contains valuable information for Cyber Threat Intelligence (CTI). This can be used to prevent attacks that have already taken place on other systems. Ideally, only the initial attack succeeds and all subsequent ones are detected and stopped. But while there are different standards to exchange this information, a lot of it is shared in articles or blog posts in non-standardized ways. Manually scanning through multiple online portals and news pages to discover new threats and extracting them is a time-consuming task. To automize parts of this scanning process, multiple papers propose extractors that use Natural Language Processing (NLP) to extract Indicators of Compromise (IOCs) from documents. However, while this already solves the problem of extracting the information out of documents, the search for these documents is rarely considered. In this paper, a new focused crawler is proposed called ThreatCrawl, which uses Bidirectional Encoder Representations from Transformers (BERT)-based models to classify documents and adapt its crawling path dynamically. While ThreatCrawl has difficulties to classify the specific type of Open Source Intelligence (OSINT) named in texts, e.g., IOC content, it can successfully find relevant documents and modify its path accordingly. It yields harvest rates of up to 52%, which are, to the best of our knowledge, better than the current state of the art.
CySecBERT: A Domain-Adapted Language Model for the Cybersecurity Domain
Dec 06, 2022



The field of cybersecurity is evolving fast. Experts need to be informed about past, current and - in the best case - upcoming threats, because attacks are becoming more advanced, targets bigger and systems more complex. As this cannot be addressed manually, cybersecurity experts need to rely on machine learning techniques. In the texutual domain, pre-trained language models like BERT have shown to be helpful, by providing a good baseline for further fine-tuning. However, due to the domain-knowledge and many technical terms in cybersecurity general language models might miss the gist of textual information, hence doing more harm than good. For this reason, we create a high-quality dataset and present a language model specifically tailored to the cybersecurity domain, which can serve as a basic building block for cybersecurity systems that deal with natural language. The model is compared with other models based on 15 different domain-dependent extrinsic and intrinsic tasks as well as general tasks from the SuperGLUE benchmark. On the one hand, the results of the intrinsic tasks show that our model improves the internal representation space of words compared to the other models. On the other hand, the extrinsic, domain-dependent tasks, consisting of sequence tagging and classification, show that the model is best in specific application scenarios, in contrast to the others. Furthermore, we show that our approach against catastrophic forgetting works, as the model is able to retrieve the previously trained domain-independent knowledge. The used dataset and trained model are made publicly available
Common Vulnerability Scoring System Prediction based on Open Source Intelligence Information Sources
Oct 05, 2022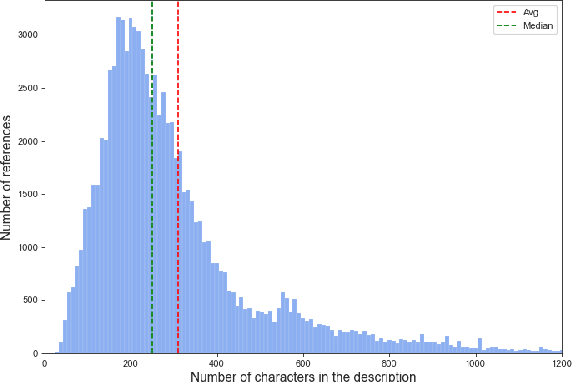
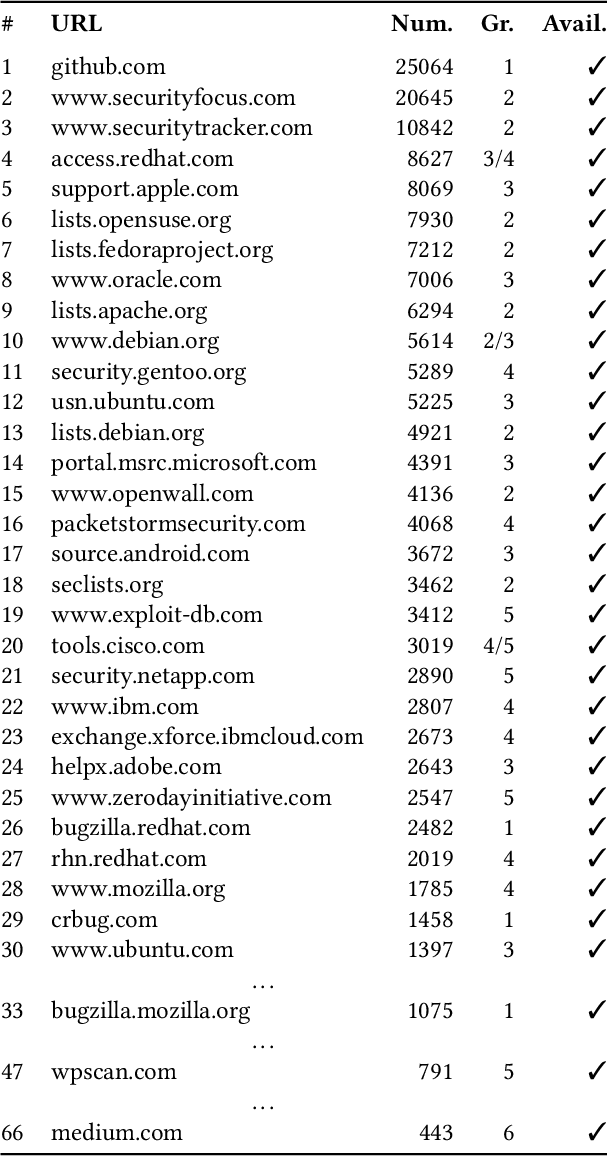
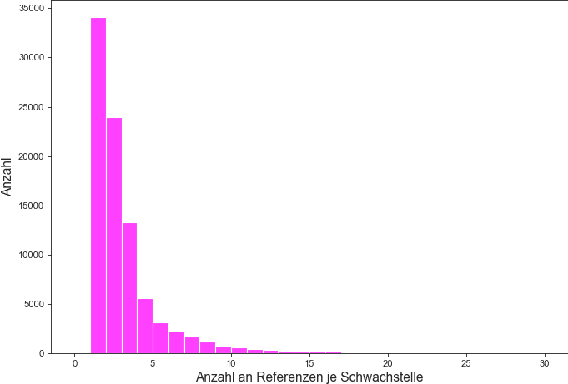
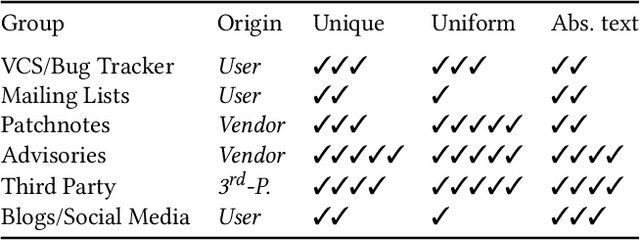
The number of newly published vulnerabilities is constantly increasing. Until now, the information available when a new vulnerability is published is manually assessed by experts using a Common Vulnerability Scoring System (CVSS) vector and score. This assessment is time consuming and requires expertise. Various works already try to predict CVSS vectors or scores using machine learning based on the textual descriptions of the vulnerability to enable faster assessment. However, for this purpose, previous works only use the texts available in databases such as National Vulnerability Database. With this work, the publicly available web pages referenced in the National Vulnerability Database are analyzed and made available as sources of texts through web scraping. A Deep Learning based method for predicting the CVSS vector is implemented and evaluated. The present work provides a classification of the National Vulnerability Database's reference texts based on the suitability and crawlability of their texts. While we identified the overall influence of the additional texts is negligible, we outperformed the state-of-the-art with our Deep Learning prediction models.