 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Data Augmentation for Text Classification
Jul 14, 2021
Data augmentation, the artificial creation of training data for machine learning by transformations, is a widely studied research field across machine learning disciplines. While it is useful for increasing the generalization capabilities of a model, it can also address many other challenges and problems, from overcoming a limited amount of training data over regularizing the objective to limiting the amount data used to protect privacy. Based on a precise description of the goals and applications of data augmentation (C1) and a taxonomy for existing works (C2), this survey is concerned with data augmentation methods for textual classification and aims to achieve a concise and comprehensive overview for researchers and practitioners (C3). Derived from the taxonomy, we divided more than 100 methods into 12 different groupings and provide state-of-the-art references expounding which methods are highly promising (C4). Finally, research perspectives that may constitute a building block for future work are given (C5).
Data Augmentation in Natural Language Processing: A Novel Text Generation Approach for Long and Short Text Classifiers
Mar 26, 2021
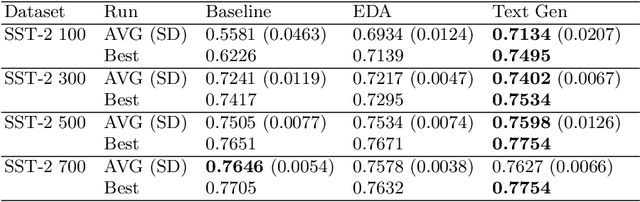

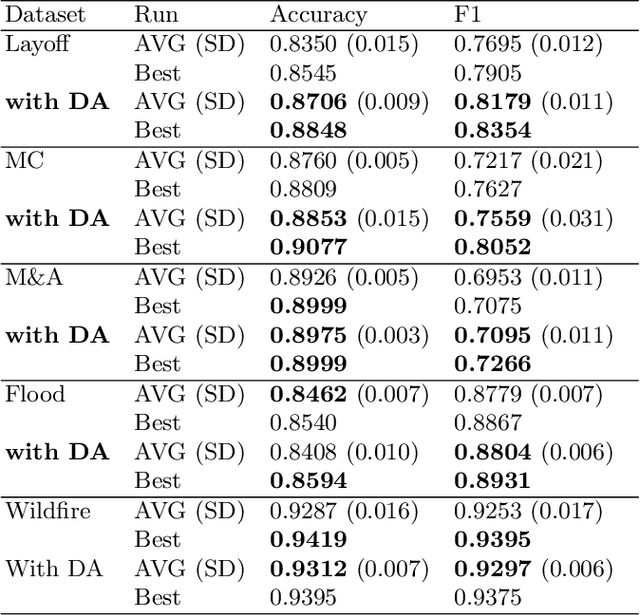
In many cases of machine learning, research suggests that the development of training data might have a higher relevance than the choice and modelling of classifiers themselves. Thus, data augmentation methods have been developed to improve classifiers by artificially created training data. In NLP, there is the challenge of establishing universal rules for text transformations which provide new linguistic patterns. In this paper, we present and evaluate a text generation method suitable to increase the performance of classifiers for long and short texts. We achieved promising improvements when evaluating short as well as long text tasks with the enhancement by our text generation method. In a simulated low data regime additive accuracy gains of up to 15.53% are achieved. As the current track of these constructed regimes is not universally applicable, we also show major improvements in several real world low data tasks (up to +4.84 F1 score). Since we are evaluating the method from many perspectives, we also observe situations where the method might not be suitable. We discuss implications and patterns for the successful application of our approach on different types of datasets.