 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure Quantized Training for Deep Learning
Jul 01, 2021

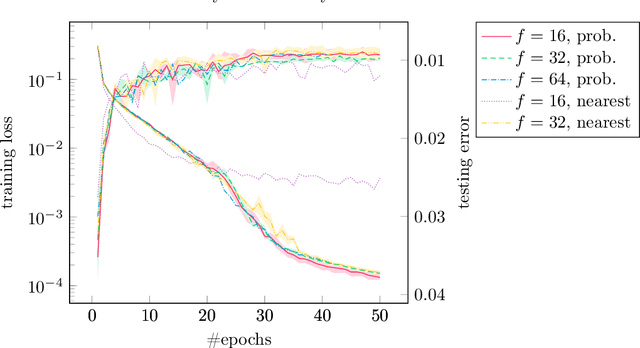
We have implemented training of neural networks in secure multi-party computation (MPC) using quantization commonly used in the said setting. To the best of our knowledge, we are the first to present an MNIST classifier purely trained in MPC that comes within 0.2 percent of the accuracy of the same convolutional neural network trained via plaintext computation. More concretely, we have trained a network with two convolution and two dense layers to 99.2% accuracy in 25 epochs. This took 3.5 hours in our MPC implementation (under one hour for 99% accuracy).
Data Augmentation in Natural Language Processing: A Novel Text Generation Approach for Long and Short Text Classifiers
Mar 26, 2021
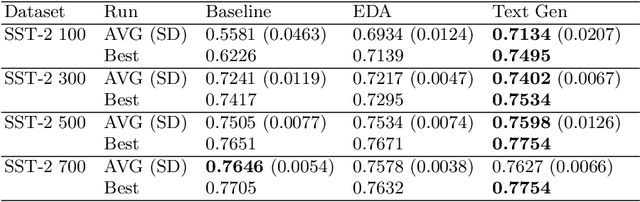

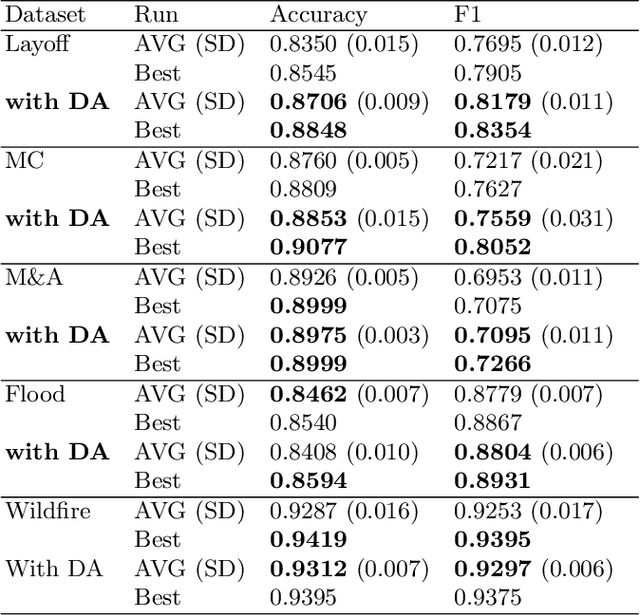
In many cases of machine learning, research suggests that the development of training data might have a higher relevance than the choice and modelling of classifiers themselves. Thus, data augmentation methods have been developed to improve classifiers by artificially created training data. In NLP, there is the challenge of establishing universal rules for text transformations which provide new linguistic patterns. In this paper, we present and evaluate a text generation method suitable to increase the performance of classifiers for long and short texts. We achieved promising improvements when evaluating short as well as long text tasks with the enhancement by our text generation method. In a simulated low data regime additive accuracy gains of up to 15.53% are achieved. As the current track of these constructed regimes is not universally applicable, we also show major improvements in several real world low data tasks (up to +4.84 F1 score). Since we are evaluating the method from many perspectives, we also observe situations where the method might not be suitable. We discuss implications and patterns for the successful application of our approach on different types of datasets.
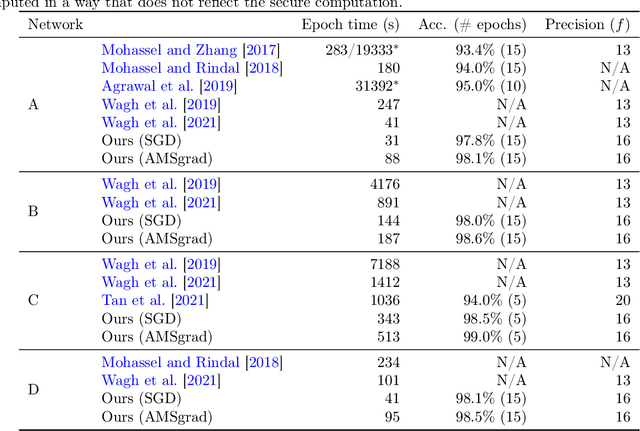
Effectiveness of MPC-friendly Softmax Replacement
Nov 23, 2020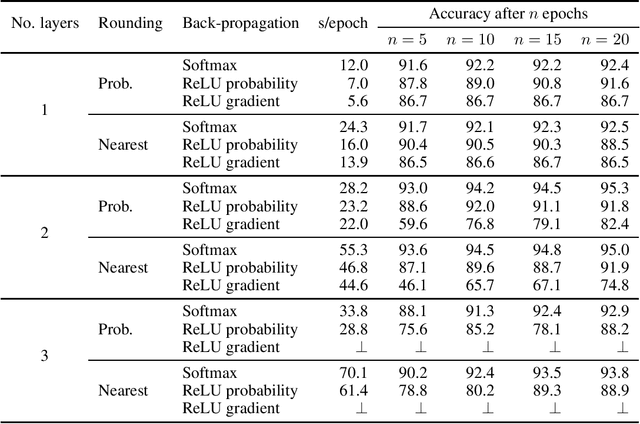

Softmax is widely used in deep learning to map some representation to a probability distribution. As it is based on exp/log functions that is relatively expensive in multi-party computation, Mohassel and Zhang (2017) proposed a simpler replacement based on ReLU to be used in secure computation. However, we could not reproduce the accuracy they reported for training on MNIST with three fully connected layers. Later works (e.g., Wagh et al., 2019 and 2021) used the softmax replacement not for computing the output probability distribution but for approximating the gradient in back-propagation. In this work, we analyze the two uses of the replacement and compare them to softmax, both in terms of accuracy and cost in multi-party computation. We found that the replacement only provides a significant speed-up for a one-layer network while it always reduces accuracy, sometimes significantly. Thus we conclude that its usefulness is limited and one should use the original softmax function instead.
Secure Evaluation of Quantized Neural Networks
Oct 28, 2019
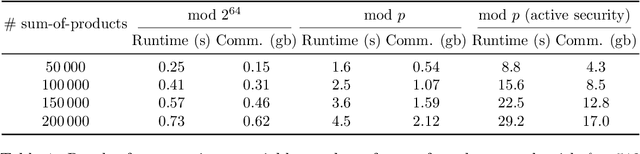
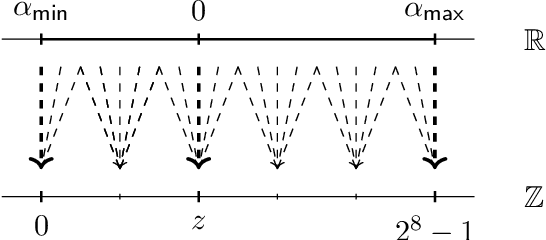

Image classification using Deep Neural Networks that preserve the privacy of both the input image and the model being used, has received considerable attention in the last couple of years. Recent work in this area have shown that it is possible to perform image classification with realistically sized networks using e.g., Garbled Circuits as in XONN (USENIX '19) or MPC (CrypTFlow, Eprint '19). These, and other prior work, require models to be either trained in a specific way or postprocessed in order to be evaluated securely. We contribute to this line of research by showing that this postprocessing can be handled by standard Machine Learning frameworks. More precisely, we show that quantization as present in Tensorflow suffices to obtain models that can be evaluated directly and as-is in standard off-the-shelve MPC. We implement secure inference of these quantized models in MP-SPDZ, and the generality of our technique means we can demonstrate benchmarks for a wide variety of threat models, something that has not been done before. In particular, we provide a comprehensive comparison between running secure inference of large ImageNet models with active and passive security, as well as honest and dishonest majority. The most efficient inference can be performed using a passive honest majority protocol which takes between 0.9 and 25.8 seconds, depending on the size of the model; for active security and an honest majority, inference is possible between 9.5 and 147.8 seconds.
A Note on Our Submission to Track 4 of iDASH 2019
Oct 24, 2019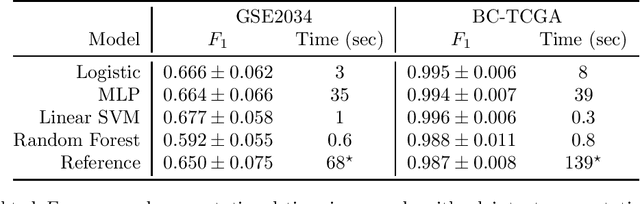
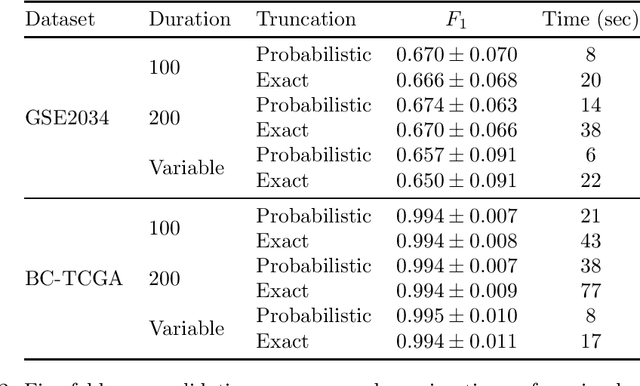
iDASH is a competition soliciting implementations of cryptographic schemes of interest in the context of biology. In 2019, one track asked for multi-party computation implementations of training of a machine learning model suitable for two datasets from cancer research. In this note, we describe our solution submitted to the competition. We found that the training can be run on three AWS c5.9xlarge instances in less then one minute using MPC tolerating one semi-honest corruption, and less than ten seconds at a slightly lower accuracy.