 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-in-the-Loop LLM Grading for Handwritten Mathematics Assessments
Mar 13, 2026Providing timely and individualised feedback on handwritten student work is highly beneficial for learning but difficult to achieve at scale. This challenge has become more pressing as generative AI undermines the reliability of take-home assessments, shifting emphasis toward supervised, in-class evaluation. We present a scalable, end-to-end workflow for LLM-assisted grading of short, pen-and-paper assessments. The workflow spans (1) constructing solution keys, (2) developing detailed rubric-style grading keys used to guide the LLM, and (3) a grading procedure that combines automated scanning and anonymisation, multi-pass LLM scoring, automated consistency checks, and mandatory human verification. We deploy the system in two undergraduate mathematics courses using six low-stakes in-class tests. Empirically, LLM assistance reduces grading time by approximately 23% while achieving agreement comparable to, and in several cases tighter than, fully manual grading. Occasional model errors occur but are effectively contained by the hybrid design. Overall, our results show that carefully embedded human-in-the-loop LLM grading can substantially reduce workload while maintaining fairness and accuracy.
Early Evidence of Vibe-Proving with Consumer LLMs: A Case Study on Spectral Region Characterization with ChatGPT-5.2 (Thinking)
Feb 21, 2026Large Language Models (LLMs) are increasingly used as scientific copilots, but evidence on their role in research-level mathematics remains limited, especially for workflows accessible to individual researchers. We present early evidence for vibe-proving with a consumer subscription LLM through an auditable case study that resolves Conjecture 20 of Ran and Teng (2024) on the exact nonreal spectral region of a 4-cycle row-stochastic nonnegative matrix family. We analyze seven shareable ChatGPT-5.2 (Thinking) threads and four versioned proof drafts, documenting an iterative pipeline of generate, referee, and repair. The model is most useful for high-level proof search, while human experts remain essential for correctness-critical closure. The final theorem provides necessary and sufficient region conditions and explicit boundary attainment constructions. Beyond the mathematical result, we contribute a process-level characterization of where LLM assistance materially helps and where verification bottlenecks persist, with implications for evaluation of AI-assisted research workflows and for designing human-in-the-loop theorem proving systems.
Cost-Sensitive Stacking: an Empirical Evaluation
Jan 04, 2023Many real-world classification problems are cost-sensitive in nature, such that the misclassification costs vary between data instances. Cost-sensitive learning adapts classification algorithms to account for differences in misclassification costs. Stacking is an ensemble method that uses predictions from several classifiers as the training data for another classifier, which in turn makes the final classification decision. While a large body of empirical work exists where stacking is applied in various domains, very few of these works take the misclassification costs into account. In fact, there is no consensus in the literature as to what cost-sensitive stacking is. In this paper we perform extensive experiments with the aim of establishing what the appropriate setup for a cost-sensitive stacking ensemble is. Our experiments, conducted on twelve datasets from a number of application domains, using real, instance-dependent misclassification costs, show that for best performance, both levels of stacking require cost-sensitive classification decision.
To do or not to do: cost-sensitive causal decision-making
Jan 05, 2021
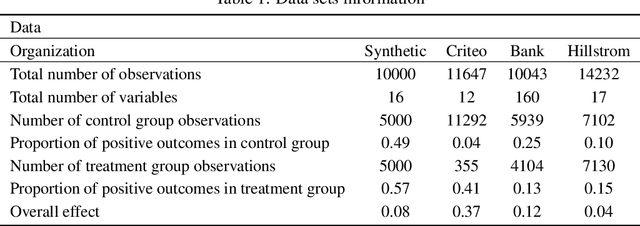

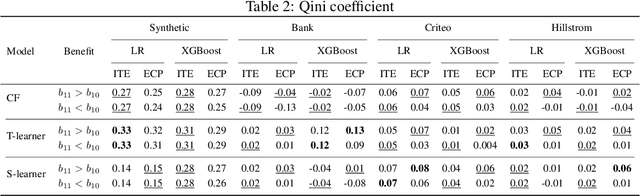
Causal classification models are adopted across a variety of operational business processes to predict the effect of a treatment on a categorical business outcome of interest depending on the process instance characteristics. This allows optimizing operational decision-making and selecting the optimal treatment to apply in each specific instance, with the aim of maximizing the positive outcome rate. While various powerful approaches have been presented in the literature for learning causal classification models, no formal framework has been elaborated for optimal decision-making based on the estimated individual treatment effects, given the cost of the various treatments and the benefit of the potential outcomes. In this article, we therefore extend upon the expected value framework and formally introduce a cost-sensitive decision boundary for double binary causal classification, which is a linear function of the estimated individual treatment effect, the positive outcome probability and the cost and benefit parameters of the problem setting. The boundary allows causally classifying instances in the positive and negative treatment class to maximize the expected causal profit, which is introduced as the objective at hand in cost-sensitive causal classification. We introduce the expected causal profit ranker which ranks instances for maximizing the expected causal profit at each possible threshold for causally classifying instances and differs from the conventional ranking approach based on the individual treatment effect. The proposed ranking approach is experimentally evaluated on synthetic and marketing campaign data sets. The results indicate that the presented ranking method effectively outperforms the cost-insensitive ranking approach and allows boosting profitability.