 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Sensitive Stacking: an Empirical Evaluation
Jan 04, 2023Many real-world classification problems are cost-sensitive in nature, such that the misclassification costs vary between data instances. Cost-sensitive learning adapts classification algorithms to account for differences in misclassification costs. Stacking is an ensemble method that uses predictions from several classifiers as the training data for another classifier, which in turn makes the final classification decision. While a large body of empirical work exists where stacking is applied in various domains, very few of these works take the misclassification costs into account. In fact, there is no consensus in the literature as to what cost-sensitive stacking is. In this paper we perform extensive experiments with the aim of establishing what the appropriate setup for a cost-sensitive stacking ensemble is. Our experiments, conducted on twelve datasets from a number of application domains, using real, instance-dependent misclassification costs, show that for best performance, both levels of stacking require cost-sensitive classification decision.
Misclassification cost-sensitive ensemble learning: A unifying framework
Jul 14, 2020

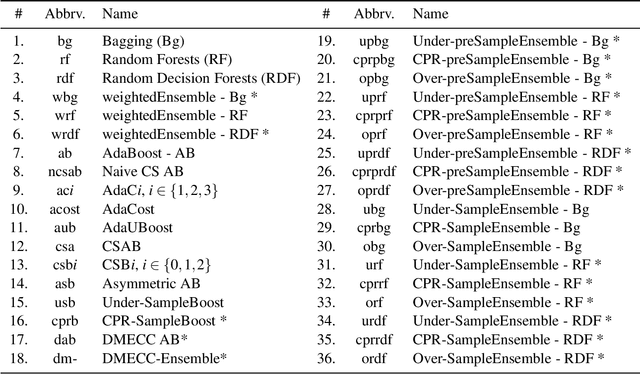

Over the years, a plethora of cost-sensitive methods have been proposed for learning on data when different types of misclassification errors incur different costs. Our contribution is a unifying framework that provides a comprehensive and insightful overview on cost-sensitive ensemble methods, pinpointing their differences and similarities via a fine-grained categorization. Our framework contains natural extensions and generalisations of ideas across methods, be it AdaBoost, Bagging or Random Forest, and as a result not only yields all methods known to date but also some not previously considered.